

Git之旅(1):版本管理,了解一下
我创建了一个文件,test.txt,我在这个文件中写入了一行文本,文本如下
$cat test.txt
abcdefg
文件中只有一行字母。
现在,我又在这个文件中瞎写了一行数字。
$cat test.txt
abcdefg
123456
此时,文件中有两行文本了,但是,我突然又不想要第二行数字了,我想让这个文件中的文本回到上一个状态,就是说,我想让文件回到只有第一行字母的状态,怎么办呢?最简单的办法就是把第二行给删了,没错,这样做完美的解决了我的问题,但是,我之所以能这样做,就是因为文本太少,改动也太少,所以,很容易就让文件变回了之前的某个状态,但是如果文件中的文本有几百行,我改了其中的几十,当我再想回到修改几十行之前的状态,就麻烦了,因为我可能已经忘记了我修改了哪些地方,所以,保险的办法是我应该在修改之前,将文件拷贝出一个副本,然后再去修改,这样,无论我修改了多少行,无论我修改了多少次,就都能够回到备份时的状态了。
上述过程只是针对一个文件的版本管理,在实际使用的过程中,我们经常需要对一堆文件进行管理,这些文件之前通常还有关联关系,比如,你将一段代码写到了A文件中,A文件中的代码如果需要正常运行,还需要依赖B文件中的某段代码,在星期一,你修改了A文件中的代码,但是没有修改B文件中的代码,在星期二,你同时修改了A文件中的代码和B文件中的代码,在星期三,你只修改了B文件中的代码,没有修改A文件中的代码,如果你在星期三时想要获取到星期一时A文件和B文件中的代码,纯靠记忆恢复,几乎完全不可能,起码我是做不到的,如果让你手动实现版本管理,你会怎么做呢?如果是我,我只会用最笨的办法,就是每天早上开始工作之前,先拷贝一个副本出来,然后再将这个副本好好保存起来,以备不时之需。
好吧,我通过笨办法,每天创建一个副本,这样可以保证我可以通过文件系统中的日期,找到之前某一天的所有代码的状态,日积月累,我写的代码文件越来越多,我昨天备份的副本中有30多个目录,有80多个文件,看着这些代码文件,我的成就感油然而生,这时,我想要对比一下,昨天备份的副本与7天前备份的副本之间有哪些不同,我该怎么办呢?昨天的副本可能比7天前的副本多了一些文件(新增文件),同时又少了一些文件(删除文件),而且即使文件名相同,其中的内容也被修改过(编辑文件),其中的目录结构也可能发生过变化,我想要对比昨天的副本和7天前的副本,我到底该怎么做呢?好吧,我放弃了,光是想想,就让人觉得头大。
看来,我急需一款能够帮助我进行版本管理的软件,靠我聪明的脑子是没戏了。
我需要一款软件,能够在我需要时,帮助我"回到过去",把文件或目录恢复到之前的某个"状态",这个软件还能够让我对比文件或目录的"当前状态"和"过去的某个状态",甚至任意两个我想要对比的"状态",你可以把我这里所说的"状态"理解成我之前保存的"副本"。
我在互联网上搜索了一下,现在最流行的版本管理软件就是Git,而且经过了解我发现,Git能完美的解决我的问题,我现在苦恼的根本原因就是,怎样管理这些文件和目录的"状态",也就是笨办法中的"副本",Git就能化解我的苦恼,只不过,使用Git以后,我不需要再通过手动复制文件的方式创建副本了,Git能够通过另一种更加灵活方便的方式,让我们的文件和目录回到过去的任意一个"状态"。
好了,如果你跟我有一样的苦恼,那么让我们一起来由浅入深的使用git吧,下篇文章我们就开始动手安装git。
Git之旅(2):安装Git
在windows中安装
在windows上和mac上安装git都很方便,我们可以从官方网站上下载安装包,按照默认配置快速安装(一直下一步),访问git官网,即可下载git,git的官方网址如下:
https://git-scm.com/downloads
在windows中安装git的过程中,如果你没有修改默认的设置,当安装完成后,安装程序会自动为你安装两种客户端,一种是图形化的客户端,一种是命令行的客户端,图形化的客户端被称之为"Git GUI",命令行的客户端被称之为"Git Bash",在系统的"开始"菜单中可以找到"Git GUI"和"Git Bash",同时,默认情况下,当你安装完成git后,你的右键菜单中会多出两个选项,"Git GUI Here"和"Git Bash Here",通过这两项,你可以在任何目录中打开"Git GUI"和"Git Bash","Git GUI"和"Git Bash"都是客户端程序,我们可以通过这两种程序中的任意一种来操作git,从而达到版本控制的目的,这两种工具在不同的使用场景下各有优势,命令行的优势在于比较通用,而且当你需要编写一些版本控制的自动化脚本时,无可避免的需要使用git命令,使用图形化的好处就是比较直观,所以,我们有可能会交替的使用这两种工具,但是主要以命令行的使用模式为主,因为只要理解了相关概念和git命令后,再去使用任何一种图形化工具,都是非常简单的。
除了gitk(默认安装的图形化客户端就包含了gitk),比较出名的git图形化工具还有SourceTree、TortoiseGit、GitHubDesktop、GitKraken、GitUp等,当你熟悉了git命令以后,再去操作这些图形化工具都会变得游刃有余。
安装工作完成后,还需要一些初始化的设置,才能开始使用git,配置方法见下文。
在centos中安装git
在linux中,有可能已经自动安装了git,也有可能没有,当服务器中的某些脚本需要使用git命令时,我们就需要确保服务器上已经安装了git,此处以centos7为例,演示怎样安装git。
即使你的centos7中默认安装了git,git的版本应该也是1.X,因为默认的yum源中,git的版本就是1.X,到目前为止,这个版本应该算是比较老的版本了,所以,如果你的centos7上没有安装git,而你又需要安装git,可以直接安装git的2.X版本。
你可以通过编译源码的方式安装git的最新版,也可以通过yum源的方式安装git,此处演示yum源方式的安装与配置,此时,我的centos7上还没有任何版本的git,安装配置过程如下:
yum install -y git
初始化配置
如果想要使用git进行版本管理,我们首先要做的就是,设置自己的"用户名"和"用户邮箱",这些信息是必须的,特别是在多人协作时,这些信息也是非常必要的,所以,在完成安装操作以后,我们首先要做的就是设置自己的"用户名"和"用户邮箱",这些信息只需要设置一次,就可以一直正常的使用git,除非你有需要修改这些信息。
我们可以使用如下两条命令,设置用户名和邮箱
注:我的系统是win10,你可以打开"Git Bash",然后执行下列命令,也可以使用win10自带的终端(比如power shell)执行如下命令,在Linux、Unix或Mac中,打开系统自带的终端输入如下命令即可。
$git config --global user.name "liqinghai"
$git config --global user.email "liqinghai@aaa.com"
将上述命令中的用户名和邮箱修改成你自己的用户名和邮箱即可,上述命令不言自明,看字面意思就能理解,git config命令是用来对git进行配置操作的一条命令,user.name和user.email分别用来设定用户名和邮箱,至于"--global"选项是什么意思,在之后的文章中再去解释,此处不要在意这些细节。
你随时可以使用如下命令,查看自己的用户名和邮箱设置
$git config --global --list
当我们执行完上述初始化设置,即可开始我们的git之旅了
Git之旅(3):仓库
当我们需要使用git进行版本管理时,要接触的第一个概念就是"仓库",你可以把"仓库"理解成一个目录,只有这个目录中的文件才能被git管理,换句话说就是,如果你想要对某个文件进行版本管理,你就需要把这个文件放入到一个带有git功能的目录中,这个带有git功能的目录就是所谓的git仓库,git仓库的英文为"git repository",后文中所提到"仓库"、"版本库"、"repository"、"repo"其实都是一种东西,我们会不加区分的使用这些名词,它们都表示"仓库",当你把一个文件加入到某个git仓库以后,你对这个文件的所有操作都可以被git记录,从而实现版本管理的目的。
所以,为了使用git进行版本管理,我们首先要做的,就是创建一个git repository。
我们可以直接创建一个空的git仓库,也可以将一个已经存在目录转化成git仓库,我们先来看看怎样创建一个全新的、空的git仓库(操作系统为win10)。
假设,我想要在"D:\workspace\git"目录中创建一个名为git_test的版本库,该怎么办呢?
首先,我们需要进入到"D:\workspace\git"目录中,你可以打开"Git Bash",然后输入如下命令进入目录
$ cd /d/workspace/git
注:在windows的git bash中,D盘对应的路径为/d/
你也可以在windows的资源管理器中打开"D:\workspace\git"目录,然后在目录的空白处单击鼠标右键,然后单击右键菜单中的"Git Bash Here",通过这种方式打开的git bash终端默认就在对应的目录中。
注:在后文中,我们输入的所有命令都是在git bash中执行的,如有特殊情况,则会说明,之后不再赘述。
当进入到对应目录后,执行如下命令即可创建git_test仓库:
$ git init git_test
Initialized empty Git repository in D:/workspace/git/git_test/.git/
没错,非常简单,执行完上述命令后,"D:\workspace\git"目录中会多出一个名为"git_test"的目录,这个目录就是一个git仓库,你可以将需要进行版本管理的文件放入到"git_test"目录中,从上述命令的返回值也可以看出,我们已经成功的初始化了一个空的git仓库。
进入刚才创建的git仓库,也就是"/d/workspace/git/git_test"这个目录,你会发现一个名为".git"的隐藏目录
$ pwd
/d/workspace/git/git_test
$ ls -a
./ ../ .git/
这个目录非常重要,git会依靠这个目录进行版本管理的工作,git会将版本管理所需的相关信息转化成git对象存放到这个目录中,其实,这个".git"目录才是真正的git仓库,这个仓库是针对git_test目录的,我们依靠它对git_test目录中的文件和目录结构进行版本管理,".git"目录赋予了git_test目录进行版本管理的能力,我们在之后的文章中会使用到这个目录,以便更加深入的理解git的运行原理,但是,需要注意,在任何时候都不要手动的修改或删除".git"目录中的文件,因为这样会破坏仓库,仓库被破坏以后,就无法进行版本管理了。
上述步骤描述了怎样创建一个新的、空的版本库,那么我们能不能把一个已经存在的目录变成一个git仓库呢?当然可以,而且更加简单,我们只需要进入到对应目录,然后执行"git init"命令即可,示例如下:
假设,我想要将"/d/workspace/git/code_test"目录变成一个git仓库,只需执行如下命令
$ cd /d/workspace/git/code_test
$ git init
执行完上述命令以后,code_test目录中就会多出一个".git"隐藏目录,此时,code_test目录就是一个可以利用git进行版本管理的目录了。
无论之前code_test目录中是否包含其他文件,我们都能够使用"git init"命令将code_test目录变为一个git仓库,即使code_test目录中原来就包含其他文件,当我们执行"git init"命令以后,code_test目录中的原有文件也不会被git管理,因为如果想要管理这些文件,我们还需要一些其他操作,才能将它们纳入到git的追踪范围以内,也就是说,git init命令只是让code_test目录拥有了版本管理的能力,无论code_test目录中原来是否存在文件,".git"目录都是新创建出来的,从git仓库的角度来说,这就是一个新的仓库,还没有任何文件被这个仓库所管理。
小结一下
git init命令是把当前目录转化成git repo
git init repo_name 命令是在当前目录中创建一个以repo_name命名的新目录,新目录是一个git repo
了解了仓库的概念以后,我们再来回顾一下上一篇文章中的知识点,我们已经说过,如果想要使用git进行版本管理,必须先提供我们用户名和电子邮箱,因为这些信息需要被记录到仓库中,我们可以使用如下命令设置用户名和邮箱
$ git config --global user.name "liqinghai"
$ git config --global user.email "liqinghai@aaa.com"
我们解释过上述两条命令的作用,但是并没有解释上述命令的"--global"选项是什么意思,现在,我们就来聊聊这个选项是什么意思。
从字面上看,"--global"的意思是"全局的",也就是说,如果我们在设置用户名和用户邮箱的时候,使用了这个选项,那么,当前系统用户(windows系统用户)创建的所有Git仓库都会使用这个用户名和邮箱,除了"--global"选项,还有"--local"选项和"--system"选项,没错,聪明如你一定想到了,我们可以通过这三个选项控制设置作用域的范围,这三个选项的作用域如下:
git config --system:使对应配置针对系统内所有的用户有效
git config --global:使对应配置针对当前系统用户的所有仓库生效
git config --local:使对应配置只针对当前仓库有效
local选项设置的优先级最高。
如果想要查看对应作用域的设置,可以使用如下命令
git config --system --list
git config --global --list
git config --local --list
我们在设置用户名和邮箱时,通常会使用"--global"选项,因为这样我们只需要设置一次,当前用户的所有仓库都会使用这些用户名和邮箱信息,即使是当前用户新创建的仓库,也会使用同样的配置,如果使用"--system"选项,可能会影响到系统中的其他系统用户,如果使用"--local"选项,当信息不需要变化时,每次创建新仓库时又都需要重复的为新仓库设置一次,所以,当设置用户名和邮箱时,"--global"选项最常用。
Git之旅(4):第一次亲密接触
如果我们需要手动的去管理版本,很有可能需要不停的创建"副本",通过"副本"的方式将各个"状态"保存下来,以便恢复到我们期望的某个"状态",其实,git的思路跟我们差不多,只不过实现方式比我们的笨办法先进太多了,不过,这并不影响我们通过笨办法的思路去学习git的使用。
所以,我们还是从笨办法的思路出发吧。
假设,我在写一个小项目,我的代码都放在一个名为project的目录中,为了保险起见,每过一会儿,我就会对project目录复制一个副本出来,然后在原目录中继续之前的工作,这样,我就能通过之前拷贝的副本,回到任意一个副本所在的状态了。
此处假设,我在2020年10月10日8点8分复制了第一个project目录的副本,为了方便描述,我们用一个圆球表示这个副本,如下图所示
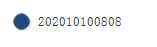
也就是说,通过这个副本,我们能在之后的任何时候,回到2020年10月10日8点8分时的状态。
过了一会,我又复制出了一个副本,此时的时间是2020年10月10日8点15分,加上之前的副本,我们已经有两个副本了,也就是说,我们已经保存了两个状态,可供我们恢复,使用下图表示我们保存的两个副本:
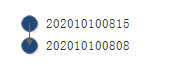
由于202010100808这个副本是我们第一个保存的副本,所以,我们把它放在最下方,表示一切的起点,就像树根一样,树长高了一点,于是有了202010100815这个副本,但是202010100815这个副本是后来的,所以,我们可以理解成,202010100815这个副本是由202010100808这个副本演变出来的,因为保存202010100808这个副本以后,我们又修改了代码,然后再次创建副本,才有了202010100815,所以,我们可以这样认为,202010100808这个状态是202010100815这个状态的父状态。
过了5分钟,我又创建副本了,好吧,我也是一个不嫌麻烦的人,于是,我们有了三个副本,如下图所示
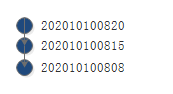
同理,202010100820这个状态的父状态是202010100815,换句话说就是,202010100808这个状态是202010100820这个状态的爷爷。
总是手动的创建副本,我真的受不了了,赶紧让git解救我吧。
我们已经创建了git_test仓库,现在,我们就把这个git_test目录当作刚才提到的project目录,从而开始我们的git之旅吧。
首先,打开"git bash"或者资源管理器,进入git_test仓库,在仓库目录中随便添加一些文件,或者目录,我们用这些文件和目录模拟最开始我编写的一些代码文件和目录结构,以便进行版本管理的相关测试。
注:我的使用习惯是所有操作都在"git bash"中进行,习惯使用vim编辑器编辑文件,你可以按照你的使用习惯创建文件、删除文件、编辑文件,只有在执行相关的git命令时,在"git bash"中执行,以便更加舒适的按照本文使用git。
我在git_test仓库中创建的测试文件如下:
$ ls
dir1/ file1 file2
$ ls dir1
d1file1
$ cat file1
1
$ cat file2
2
$ cat dir1/d1file1
d1f1
如上述信息所示,仓库目录中有两个文件,file1和file2,还有一个目录,dir1,此目录中还有一个名为d1file1的文件,这些文件中分别有一些内容,这些内容只是用于测试,并没有什么实际意义。
$ cat file1
1
$ cat file2
2
$ cat dir1/d1file1
d1f1
好了,我的项目目录中已经有这些文件了,假设这些文件就是我的代码文件,现在,我想要把当前项目的状态保存下来,以便在以后的任何时候,恢复到当前状态,我该怎么办呢?之前说过,我们通过Git管理这些文件时,不用创建副本,但是总要有一种办法能够把当前状态保存下来吧,是的,如果我们想要将一个状态保存到git仓库中,则需要借助一些git命令才行,接下来的操作你可以先大致的看一遍,以便在心里有一个大概的了解,接下来的操作中并不会有太多详细的解释,只是为了让我们对git进行版本管理的大致过程有一个感观上的认识,以便结合之前描述的概念认识git,所以,先看完整个操作过程,我们再进行进一步的讨论。
为了保存项目当前的状态,我使用如下git命令,将当前状态提交到了版本库中。
首先确保你在仓库目录中,然后执行如下命令
$ git add .
$ git commit -m "First snapshot"
你不用在意上述命令的含义,只要知道,我们通过上述命令,将当前状态保存到了版本库中即可,你可以理解成,上述两条命令帮助我们创建了一个"副本",只不过这个副本是以git对象的方式保存在了git仓库中,而不是我们手动复制出的那种"副本",我们可以通过它回到当前"状态"。
什么?你问我怎样找到这个状态?怎样查看之前保存的状态?好吧,为了更加直观的展示,我先用图形化的界面查看一下我们刚才保存的状态吧,前文说过,默认安装后,会安装一个叫gitk的图形化工具,为了更加直观的展示,我们先用这个工具演示怎样查看之前保存的状态吧,有两种方式可以打开gitk,一种是纯图形化的方式打开gitk,一种是通过命令行打开gitk,我的使用习惯是使用命令行打开gitk,因为这样非常方便,操作如下:
首先,确保你的终端路径在git仓库目录中
$ pwd
/d/workspace/git/git_test
然后直接输入gitk命令,即可打开gitk图形化操作界面
$ gitk
打开gitk图形化以后,可以看到如下图所示的一个黄色的"圆球",看到这个"圆球",是不是感觉很亲切,没错,你可以把这个"圆球"理解成上文中我们描述的蓝色"圆球",这个"圆球"就是我们刚才通过命令保存的那个"状态",从下图蓝色底色的文字中可以看到这个状态的描述信息,"First snapshot",细心如你肯定已经发现了,这正是之前使用的git命令中的信息,这个信息是对这个状态的描述,方便我们在很久以后,也能知道这个状态的大致作用是什么,指向这个圆球的,还有一个名叫"master"的东西,我们暂且不用管它是什么,先忽略它,之后我们再去了解它。
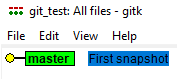
注:当你从命令行中打开gitk以后,命令行会停留在gitk命令的位置,直到你关闭了gitk的图形化界面,如果你想要在执行git命令的同时查看gitk图形化的内容,你最好再打开一个新的"Git Bash",然后在新的"Git Bash"中执行命令。
好了,我们已经保存了第一个"状态",即使从现在开始我把代码改乱了,也能通过这个状态快速的恢复了(恢复操作是后话,不用纠结)。因为当前状态已经保存了,所以我们已经没有了后顾之忧,我们现在可以继续工作了,那么,我随便修改一个文件的内容,模拟一下我们继续工作的样子,假装我们又写了很多代码,操作如下:
$ cat file1
1
$ echo '11' >> file1
$ cat file1
1
11
我通过上述命令,在file1文件中多加入了一行文本,这行文本就是我新开发的代码,假设,我现在又想要将当前项目的状态保存下来,已被不时之需,我只需要执行如下git命令即可(你仍然不需要在意这些命令的含义,先有个大概印象即可):
$ git add .
$ git commit -m "Second snapshot"
好了,我们又保存了一个新的状态,那么我们再来通过gitk查看一下这些状态吧。
再次打开gitk界面(如果你没有关闭之前的gitk,可以按F5快捷键刷新),如下图所示
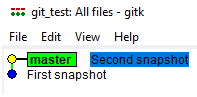
从上图可以看出,现在已经有两个"圆球"了,这两个圆球分别代表我们保存的两次状态,你可以把它们理解成我们手动创建的"副本",跟我们使用"笨办法"时的思路一样,"Second snapshot"这个状态其实是由 "First snapshot"这个状态演化而来的,所以,"First snapshot"状态是"Second snapshot"状态的父状态,我们为了方便理解,一直将这些"圆球"称之为"状态",在git中,它有另外一个名字,它在git中被称之为"commit",中文名叫"提交",也就是说,每一个这样的"圆球",都代表一次"提交",之所以被称之为提交,是因为如果想要将某个状态保存下来,就需要提交到版本库中,正如我们上文中使用的git commit命令,这个命令就是来负责将之前改动的内容提交到版本库的。
那么我们再来修改一些内容,然后尝试再次提交。
假装我们又在file1中写了一些代码,并且创建了新的文件,file3
$ echo 111 >> file1
$ echo 3 > file3
$ ls
dir1/ file1 file2 file3
$ cat file1
1
11
111
$ cat file3
3
好了,我们又写了一些"新代码",并且创建了一个新文件,也就是说,从上一次提交以后,我们又做了一些修改,如果我们想要将修改后的状态再次保存,就还需再次进行提交的操作,聪明如你一定想到了,其实我们每次提交,都是在保存上一次提交之后的"变更",或者称之为"变更集"更为合适,因为自从上次提交以后,我们可能已经进行了非常多的操作,我们可以将这些操作作为一个"变更集合",一次性的提交到仓库中,就像我刚才所做的那样,我修改了file1,创建了file3,这些操作都是所谓的变更,你可以认为这是两个变更,如果我再次进行提交,可以将这"两个变更"作为一个"变更集合",一次性提交到git仓库中,好了,说了这么多,我们还没有进行第三次提交,我们赶紧行动吧,执行如下命令,将上述两个变更作为一个变更集,提交到仓库中。
$ git add -A
$ git commit -m "modified file1 and add new file: file3"
你可能会问,为什么每次执行"git commit"命令之前都要执行一个"git add"命令呢?其实,"git add"命令就是用来操作变更集的,当存在多个变更时,我们可以利用"git add"命令,选择将哪些变更加入到本次提交的变更集合中,也就是说,并不是每次提交都要将所有的变更都提交,而是可以有选择性的,只有被加入到变更集中的变更才会被提交, 只不过,上例中的"git add -A"命令并没有进行选择,而是将所有变更作为了一个变更集合,当"git add"命令创建出这个变更集以后,"git commit"命令将这个变更集合提交到了git仓库中。
关于"git add"命令和"git commit"命令我们还有很多话题可以聊,所以不要着急,我们只要对它们有一个初步印象即可。
完成上述步骤后,我们已经有了3个提交,打开gitk,如下图所示
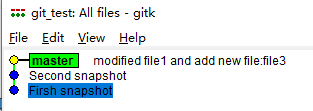
如果以后,我想要回到这三个版本中的任何一个,就靠它们了!
Git之旅(5):越了解,越喜欢
我们已经初步的使用了git,我们通过创建"提交"的方式将某个状态保存下来,"提交"就相当于我们手动管理版本时所创建的"副本",但是,"提交"其实比"副本"高明的多,那么到底高明在哪里呢?我们一起来看看。
首先,来说说手动进行版本管理时所创建的副本。
假设,我的代码都放在一个名为project的目录中,现在project目录中有很多文件,总共占用磁盘空间2M,现在,我想要修改其中的一些代码文件,为了整个项目能够随时恢复到当前状态,我需要手动的创建一个副本,于是,我将整个项目目录拷贝了一份,这个副本也占据了2M磁盘空间,于是我开始了修改工作,修改工作完成后,我觉得修改后的状态也需要保存一下,以便随时回到这个状态,于是,我又创建了一个副本,这个副本也占据2M磁盘空间,也就是说,我每次创建副本,都是上述过程的重复,无论我修改了多少代码,即使只修改了一点点,我也需要将整个目录复制一份,以便保证目录中的所有文件在某一时刻的一致性,换句话说就是,即使两个版本之间的差异只有1k,但是也需要牺牲约2M的空间,来实现版本管理。
那么git是怎样实现版本管理的呢?git使用的方法,比我们高明的多,事实上,git只会对修改的部分创建副本,而不会对整个目录创建副本,那git是怎么做的呢?如果想要了解git是怎么做的,则需要从git对象说起,"git对象"的概念并不难理解,请坚持看完下文,看完了,自然就理解了。
当我们使用git进行版本管理时,git会将我们的文件和目录结构转化成git方便操作的数据,也就是说,git会将我们的文件和目录转化成一种叫做"git对象"的东西,然后再对这些"git对象"进行管理,从而实现版本管理的目的,这些git对象存放在git的对象库中。
我们眼中的文件会被git转化成"块"(blob)
我们眼中的目录会被git转化成"树"(tree)
我们眼中的状态会被git转化成"提交"(commit)
blob、tree、commit都是git对象,是三种不同类型的git对象
一个blob就是由一个文件转换而来,blob对象中只会存储文件的数据,而不会存储文件的元数据。
一个tree就是由一个目录转化而来,tree对象中只会存储一层目录的信息,它只存储它的直接文件和直接子目录的信息,但是子目录中的内容它并不会保存。
一个commit就是一个我们所创建的提交,它指向了一个tree,这个tree保存了某一时刻项目根目录中的直接文件信息和直接目录信息,也就是说,这个tree会指向直接文件的blob对象,并且指向直接子目录的tree对象,子目录的tree对象又指向了子目录中直接文件的blob,以及子目录的直接子目录的tree,依此类推。
每个git对象都有一个"身份证号",这个身份证号是一个哈希码,这个哈希码通过SHA1算法得出,如果git对象的内容相同,那么他们的哈希码就是相同的,如果git对象的内容不同,那么他们的哈希码必定不同(通常来说,SHA1算法能够保证内容不同时,得到的哈希码必定不同,不过,理论上来说,即使内容不同,也有可能产生相同的哈希码,不过几率非常之小,我们可以忽略这种可能性),一个git对象的哈希码通常长成如下模样:
875925683e755d94e26a2dc1a1bc4c645a91acbe
它是一个40位的十六进制数。
刚才提到,每个git对象都有一个这样的哈希码,所以,每个"提交"(commit)也有一个这样的哈希码,在后文中,我们会使用提交的哈希码来表示某个提交,不过由于这个哈希码比较长,所以通常情况下,我们只会使用哈希码的前几位来表示一个提交,只要这个哈希码的前几位与别的哈希码的前几位不同,能体现出唯一性,我们就能用这个哈希码的前几位来表示这个提交,比如,刚才示例的哈希码如下
875925683e755d94e26a2dc1a1bc4c645a91acbe
我们可以使用8759256来表示这个哈希码。
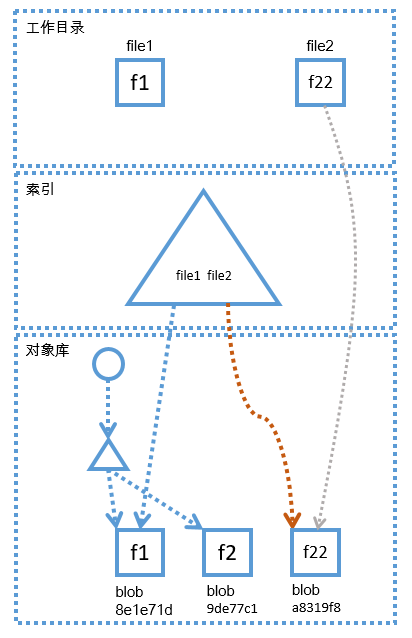
只看上面一段描述,可能不太容易理解,我们来看张图,用图来描述上述内容似乎更加容易理解,下图模仿于 [Git版本控制管理]一书,下图中的圆形代表commit(即前文中的"小圆球"),三角形代表tree(由目录转化成的git对象),长方形代表blob(由文件转化成的git对象)。假设,第一次提交之前,目录中只有两个文件,file1和file2,file1的内容为f1,file2的内容为f2,那么当第一个提交创建以后,git的对象库中会存在如下图的git对象
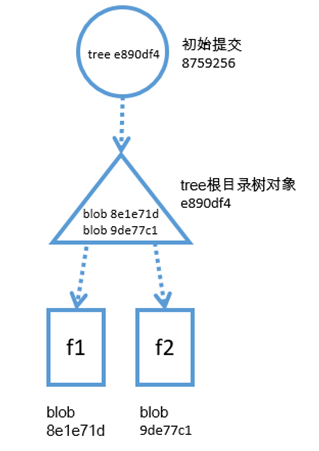
也就是说 ,当我们创建第一个提交以后,项目当时的状态已经被转化成了上图中的git对象,我们创建的第一个提交的哈希为8759256,它指向一个tree,这个tree就是当时根目录的状态,这个tree的哈希为e890df4,从上图可以看出,当时的根目录中只有两个文件,也就是两个blob,这个tree指向了这两个blob,这两个blob就是由file1和file2转化而来的。
如果此时,我们修改了file2,我们将file2的内容从f2修改成f22,并且在根目录中创建一个新的子目录dir1,在dir1中又添加了一个文件d1file1,d1file1的内容是df1,但是我们并没有对file1进行任何修改,那么,当我们再次提交以后,git对象库中会存在如下对象。
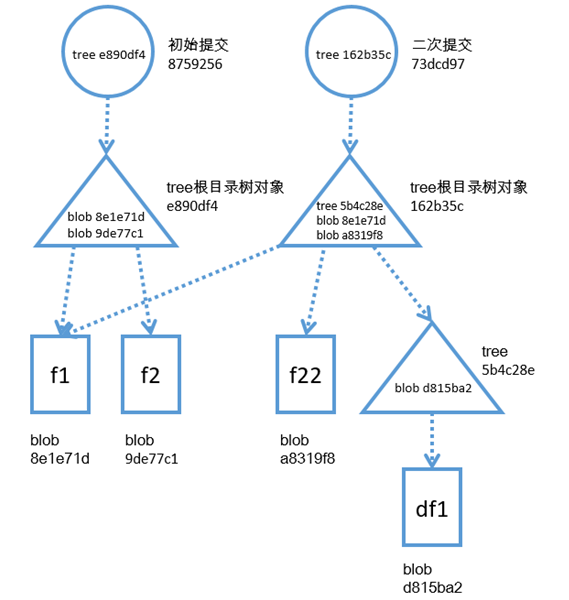
如上图所示,我们修改了file2,将其内容从f2修改成了f22,当第二个提交创建以后,git会将file2的新状态转化成一个新的blob对象,file2之前的状态对应的blob对象仍然保存在git对象库中,并且被初始提交引用,以便我们随时能够通过初始提交找到file2当时的状态,file2新的状态被新的提交引用,我们并没有修改file1,也就是说,file1的状态一直没有发生改变,所以,新的提交只是通过tree对象指向了之前file1对应的blob,由于我们在根目录中创建了一个子目录dir1,所以,在新的根目录的tree对象中,也包含了它的直接子目录信息,并且指向了新子目录对应的tree对象,子目录tree对象中又保存了自己目录中的信息,也就是d1file1文件对应的blob对象。
看完上述过程,我们回到最初的问题,当我们手动创建副本时,为了保存项目中所有文件在某一个时刻的状态的关联性和一致性,我们需要对整个项目(所有文件)创建副本,这种做法就会导致之前描述的问题发生,即使两个副本之间的差异只有1k,也需要牺牲2M的磁盘空间,每次创建副本,无论改动的大小,都会牺牲整个项目大小的磁盘空间,这样在频繁创建副本的情况下,是非常不划算的,但是git的做法就高明的多,它只会对改动的文件创建副本,就像上例中的file2,当file2的状态发生改变时,git才会对file2的新状态创建新的blob对象。
file1的状态没有发生改变,git就不会对file1创建副本,也就是说,在两个commit中(在整个项目的两个状态中)file1的状态是相同的,于是git并没有对file1重复的创建blob,而是通过引用的方式,指向了file1对应的blob,即两个副本复用了同一个file1的状态,所以,当我们使用git进行版本管理时,只会牺牲最小的磁盘空间,来实现版本管理。
我对git的理解似乎加深了,因为我明白了,一个commit就代表项目的一个状态(相当于手动创建的副本),一个commit背后是一堆git对象,git将这些git对象巧妙的组织在了一起,从而实现了版本管理的目的。
Git之旅(6):从概念到实践
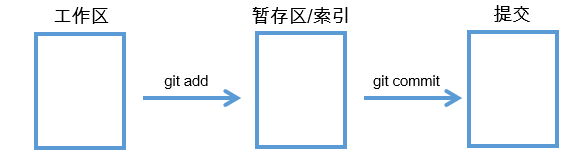
在git中,有一些"区域"的概念,我们在使用git时,其实一直都在使用这些"区域",所以,了解git"区域"的概念是必须的,这有助于我们使用git和理解git的工作原理。
从物理上来说,我们能直观的看到两个"区域",一个是"工作区",一个是"版本库"。
就拿我们之前的测试仓库举例,进入git_test仓库,你会发现一个名为".git"的隐藏目录,以及除了".git"目录的其他文件和目录,如下图所示
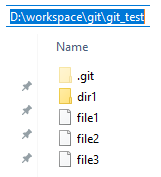
其实,上图中的".git"目录就是所谓的"版本库",而上图中除了".git"目录以外的其他文件和目录组成了"工作区",换句话说就是,进入git_test目录,排除".git"目录以后的区域就是工作区,工作区的概念非常容易理解,因为我们的实际工作就发生在这个区域,我们在这个区域创建文件和目录、编辑文件、删除文件和目录,这些操作都是在工作区完成的,而当我们需要把工作区的状态保存到版本库时,则需要借助到"版本库"区域了,也就是说,两个区域的关系如下图
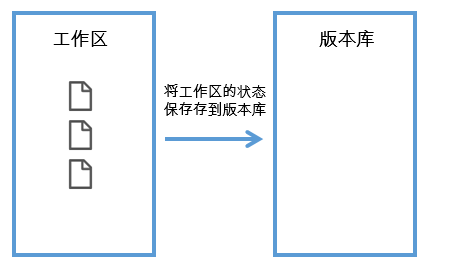
当工作区的状态保存到版本库以后,工作区的文件就会转换成blob对象,工作区的目录结构会转换成对应数量的tree对象(前文中已经总结了git对象的概念,此处不再赘述),这些git对象存储在"版本库区域"的对象库中。
不知道你还记不记得,在前文中,当我们想要将一个状态保存下来时,通常会通过类似如下两条命令创建一个提交
$ git add -A
$ git commit -m "some comment"
如你所见,上述两条命令协力将工作区的状态保存到了版本库中,也就是说,仅仅靠上述一条命令是无法完成整个操作的,前文说过,我们可以利用"git add"命令选择将哪些变更加入到下一次的提交中,其实,当我们执行"git add"命令以后,工作目录中文件的状态就已经转换成blob对象了,当我们使用"git commit"命令以后,才会创建出commit对象。
其实,在工作区和最终存储的对象之间还有一个"重要区域",这个区域被称之为"索引"或者"暂存区",而刚刚提到的"git add"命令其实就是用来操作索引区域的,如果跟前文中的对象的概念结合在一起,那么索引区域应该在下图中的如下位置
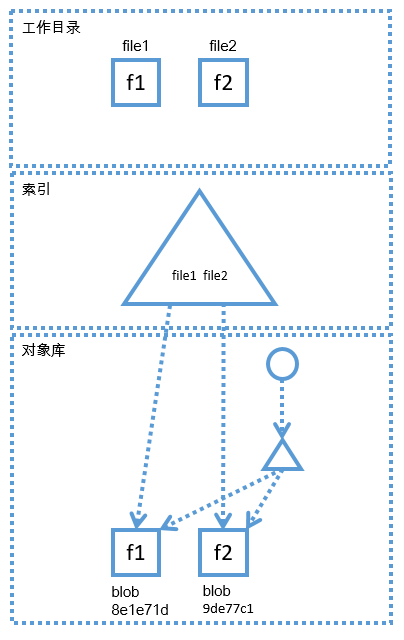
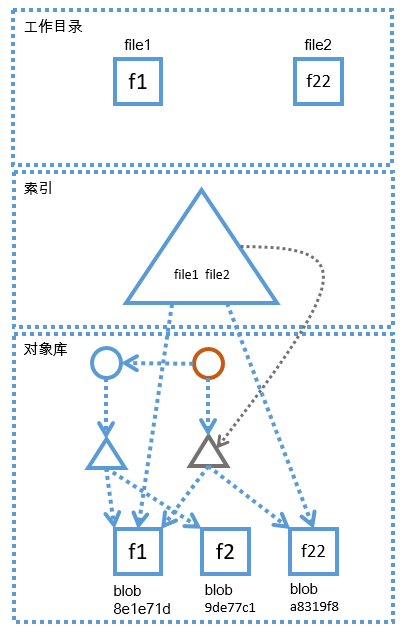
上图描述了第一次提交产生以后,各个区域的状态,从上图可以看出,工作区有两个文件,file1和file2,文件内容分别为f1和f2,在对象库区域中,第一次提交对应的commit对象(圆形)已经指向了对应的tree对象(三角形),tree对象又指向了直接子目录的blob对象,而此时,索引的结构与对象库其实是一样的,索引也指向了file1和file2对应的blob,或者说,索引中记录的file1和file2的哈希就是上图中那两个blob的哈希,目前来说,我们不用纠结索引到底是什么样的,在后文中我们会通过更加直观的方式去了解它,但是在这之前,我们先借助上图去搞明白它的概念和作用就好,只依靠上面一幅图就想完全搞明白索引的作用有些不太现实,最好坚持看完后文,再回过头来理解,就容易多了, 就目前的状态而言,索引和对象库中的状态是一致的,都指向了同样的blob。
如果此时,我们修改了工作目录中的file2文件,我们将其内容从f2改为了f22,那么此时,各个区域的状态如下图所示。
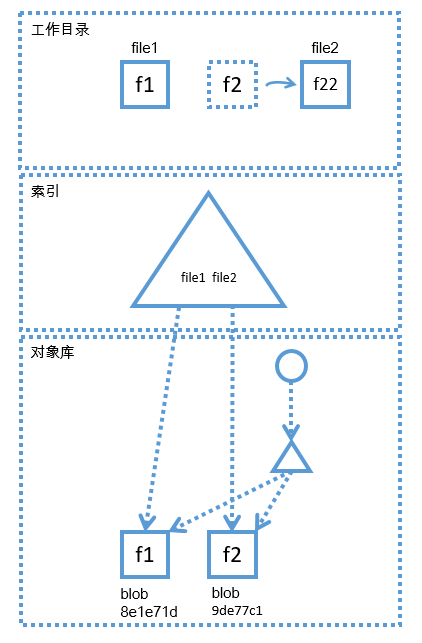
当file2的内容变化以后,工作区file2文件的状态已经发生了改变,工作区中file2的新状态已经与索引区和对象库中的状态不一致了,索引和对象库中指向的仍然是file2的内容为f2时的状态(即上图中哈希为9de77c1的blob),这时,file2的新状态对应的blob对象还没有生成,file2的新状态只存在于工作目录中,那么file2的新状态对应的blob对象是在什么时候生成的呢?刚才其实我们已经剧透了,当我们执行"git add"命令以后,对应的blob就会产生,"git add file2"命令执行后,对象库和索引区的状态如下图:
如上图所示,当"git add file2"命令执行以后,"git add"命令会做两件事,第一件要做的事就是为file2的新状态创建blob对象,也就是上图中浅灰色曲线所表示的步骤,当新的blob对象(即上图中哈希为a8319的blob对象)创建完成后,"git add"命令就会做第二件事,即更新索引,将索引中的file2指向新创建的blob对象,即上图中橘黄色曲线所表示的步骤,橘黄色的区线表示索引中的file2原来指向9de77c1,当"git add"命令执行后,索引中的file2指向了a8319f8。
此时,虽然在对象库中已经生成了file2文件的新状态对应的blob,但是仍然没有任何一个提交通过tree指向这个blob,前文一直在强调,提交(commit)代表了一个状态,我们如果想要恢复到某个状态,必须依靠提交,而上图中的a8319f8并没有任何一个commit通过tree指向它,所以,我们还差一步,就是创建提交,没错,执行"git commit"命令即可创建提交,提交命令执行后,会进行如下图中的操作
当执行提交命令以后,git会根据索引中的结构,在对象库中创建出对应的tree对象,也就是上图中灰色曲线所表示的步骤,之后,git会创建一个commit对象,并且将新创建的commit对象指向刚才新创建的tree,于是,一个新的提交产生了,它记录了一个状态,我们可以随时通过这个提交回到对应的状态,而且这个时候,索引的结构和最新的提交所对应的结构是一致的。
如上图所示,这个新创建的提交也会指向前一个提交,每个提交都会指向自己的父提交。
到目前为止,我们已经结合"git add"命令和"git commit"命令,了解了对象创建的整个过程,并且明白了,整个过程会经历多个区域,我们先是在工作区对文件进行编辑修改,然后使用"git add"命令操作暂存区(索引)和对象库,将修改后的文件状态转换成git对象,并且将暂存区的指向结构更新,以便在下载提交创建的时候,可以根据当前暂存区的结构创建出对应的tree对象,直到一个新的提交生成,也就是说,它们之间的关系如下图所示
到目前为止,我们已经了解了很多的基础概念,但是总感觉没有操作过几个git命令,不如我们来痛快一次,以命令操作为主,以解释为辅,更加清晰将概念和命令相结合吧,我们从创建仓库开始(下列操作中可能涉及一些新命令,不过在了解了上述概念以后,再看这些命令就非常容易理解了)。
初始化名为test的git仓库
$ git init test
Initialized empty Git repository in D:/workspace/git/test/.git/
进入test仓库
$ cd test
创建两个测试文件
$ echo f1 > file1
$ echo f2 > file2
使用"git status"命令可以查看哪些文件的状态有变更,按照上图中的理解就是,哪些文件在工作区的状态发生了变化,可以被加入到暂存区,以备之后创建提交,但是由于我们刚刚创建仓库,所有创建的文件都是新加入工作目录的文件,所以,当我们使用"git status"命令时(如下所示),会查看到两个"Untracked files",即"未被跟踪"的文件,从你的客户端看到的file1和file2应该是红色的字体,红色表示当前状态只存在于工作区。
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
file1
file2
nothing added to commit but untracked files present (use "git add" to track)
而且从上述提示可以看出,使用"git add"命令可以追踪这两个文件,其实,我们也可以把新增文件理解成一种状态的变更,所以,如果想要在下次提交时保存这个状态,需要先使用"git add"命令,将它们的转化成git对象,你可以执行两条git命令分别操作两个文件,如下:
$ git add file1
$ git add file2
也可以使用"git add ."命令,将当前目录中所有处于变更状态的文件一次性的加入到暂存区中,执行上述命令,再次使用"git status"命令查看状态,命令如下:
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: file1
new file: file2
在你的git bash终端中,你看到的file1和file2应该是绿色的,这表示这两个文件的状态已经被加入到了暂存区,而且从上述提示信息可以看出,"Changes to be committed"的文件有两个,这两个文件都是" new file",也就是说,新创建的commit中会提交这两个变更(chages)。
好了,现在来提交
$ git commit -m "add file1 and file2"
[master (root-commit) 116921a] add file1 and file2
2 files changed, 2 insertions(+)
create mode 100644 file1
create mode 100644 file2
提交完成后,使用如下命令查看提交历史
$ git log
commit da9c95d16f420433074a86cfb7213777ab2e1659 (HEAD -> master)
Author: lqh <lqh@zzinfor.com>
Date: Sat Oct 10 15:21:23 2020 +0800
add file1 and file2
从上述信息可以看出,我们创建的第一个提交的哈希值为da9c95d16f420433074a86cfb7213777ab2e1659
作者是lqh,作者邮箱是lqh@zzinfor.com
以及这个提交的创建日期。
好了,我们再来一遍,现在修改一下file1和file2文件,将file1的内容从f1修改为f11,将file2的内容从f2修改为f22。
$ echo f11 > file1
$ echo f22 > file2
再次使用"git status"命令查看工作区的变更,信息如下:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file1
modified: file2
no changes added to commit (use "git add" and/or "git commit -a")
由于我们修改了file1的内容和file2的内容,所以,上述信息中显示这两个文件处于modified的状态,我们可以根据需要,将这些变更加入到暂存区,如果你觉得目前两个文件的状态都需要跟随下次提交进行保存,那么你可以将这两个变更一次性加入到暂存区,如果你觉得只有file1的状态适合下次提交时保存,file2的改动还没有完全完成,还需要继续修改,那么你只将file1加入到暂存区即可,这些都是可以根据需求灵活操作的。在你的git终端中,上述变更列表应该显示为红色,红色表示这些变更仍然只存在于工作区,还没有加入到暂存区,也就是说,这些新状态还没有被转换成git对象,它们只存在于你的工作目录中。此处为了示例方便,仍然一次性将所有变更加入到暂存区,然后使用"git status"命令查看,如下。
$ git add .
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: file1
modified: file2
文件列表已经显示为绿色,证明它们已经被加入到暂存区,已经做好了被提交的准备
$ git commit -m "File 1 and file2 have been modified"
[master 3679998] File 1 and file2 have been modified
2 files changed, 2 insertions(+), 2 deletions(-)
我们现在已经有两个提交了,使用"git log"命令查看2个提交的详细信息,或者使用"git log"命令的--oneline选项,以简易模式查看提交的信息,示例如下:
$ git log --oneline
3679998 (HEAD -> master) File 1 and file2 have been modified
da9c95d add file1 and file2
简易模式中,会显示提交的哈希码,但是只显示哈希码的前几位,以及提交对应的注释信息, 最新的提交信息中会显示(HEAD -> master),这代表HEAD头指针指向了master分支,master分支指向了最新的提交,HEAD头指针和分支的概念我们后面再聊,此处不用理会它们。
当提交创建完成后,再次使用"git status"命令查看暂存区的状态,信息如下:
$ git status
On branch master
nothing to commit, working tree clean
如上述信息所示,git显示,没有什么可以提交的,工作区是干净的,也就是说,工作区的状态,暂存区的状态,提交的状态是一致的。
通过上述重复的操作,我们已经初步掌握了如下命令
"git status":查看有没有变更的状态,并且查看哪些变更已经加入了暂存区,红色的变更表示只存在于工作区,还未加入暂存区,绿色的变更表示已经加入到暂存区,这些变更将会被提交。
"git add":将需要进行提交的变更加入到暂存区。
"git commit":将所有加入暂存区的变更作为一个变更集合,创建提交。
"git log":查看提交历史,此命令有很多实用参数可以使用,利用这些参数可以通过不同的方式查看历史,后面慢慢聊,不用着急。
有没有觉得自己对上述git命令、区域的概念以及git的工作原理有了进一步的了解呢?不如我们再进一步,通过git对象的思维方式来了解一下git,静下心来,把下文看完,之前说过,每个git对象都有一个身份证号,也就是其对应的哈希值,只要我们能够获取到git对象的哈希值,就能通过哈希值获取到git对象的一些信息,比如,通过哈希值判断git对象的类型,或者通过哈希值来查看git对象的内容。那么具体怎么做呢?其实很简单,借助一些git命令就行,就拿我们最近创建的提交来举例吧。
首先,通过git log找到我们最近创建的提交,如下:
$ git log --oneline
3679998 (HEAD -> master) File 1 and file2 have been modified
da9c95d add file1 and file2
从上述信息可以看出,最近的提交的哈希值为3679998,我们可以借助"git cat-file"命令,通过哈希值判断哈希对应的git对象类型,并且查看其内容,虽然我们已经知道136146b 这个哈希值对应的是一个commit对象,但是当你只知道哈希值的时候,可以通过如下命令获取到哈希对应的对象类型:
$ git cat-file -t 3679998
commit
如上例所示,使用"git cat-file -t 哈希值"命令即可。
"git cat-file"命令的"-t"选项可以查看哈希对应的对象类型,而"git cat-file"命令的"-p"选项可以帮助我们查看git对象的相关内容。
比如,使用"git cat-file -p 哈希值"命令查看最近的提交对象的内容信息,示例如下:
$ git cat-file -p 3679998
tree 22bb0fd9a518ff8cd695d9e08c89029d55836ed2
parent da9c95d16f420433074a86cfb7213777ab2e1659
author lqh <lqh@zzinfor.com> 1602314697 +0800
committer lqh <lqh@zzinfor.com> 1602314697 +0800
File 1 and file2 have been modified
从上述返回信息可以发现,最新的commit对象指向了一个tree对象,这个tree对象的哈希是22bb0fd......,同时,这个commit对象还指向了一个叫做parent的东西,这个叫做parent的东西也有一串哈希,那么我们来看看,这个哈希到底对应的是个什么东西,如下:
$ git cat-file -t da9c95d16f420433074a86cfb7213777ab2e1659
commit
通过上述命令,我们看出这个哈希对应的其实是一个commit对象,那么我们再来看看这个对象的内容,如下:
$ git cat-file -p da9c95
tree e890df4b61259ae013926f478db558ec0098e2d5
author lqh <lqh@zzinfor.com> 1602314483 +0800
committer lqh <lqh@zzinfor.com> 1602314483 +0800
add file1 and file2
从上述信息可以发现,这个提交的注释信息是"add file1 and file2",原来这个commit对象就是我们之前创建的第一个提交,这时我突然想起来,之前说过,一般情况下,每个提交对象都会指向自己的父提交,当然,第一个提交没有父提交。
让我们把目光重新放回到最新的这次提交中,最新的提交中除了自己的父提交,还指向了一个tree对象,那么我们来看看这个tree对象中都有什么,如下:
$ git cat-file -p 22bb0fd
100644 blob 26cd2781d622faeb05993d00535f1bdd31080c28 file1
100644 blob a8319f8f9473c45a71ff86c4037a3b60a0bd1b1f file2
如上述信息所示,这个tree对象指向了两个blob对象,这两个blob对象都有自己的哈希值,这两个blob对象就是由file1文件和file2文件的状态转换而来的,你快通过"git cat-file"命令查看一下这两个git对象的内容吧,不正是f11和f22吗?
聪明如你应该已经发现了,我们通过提交的哈希,层层剥离,一直找到file1和file2对应的blob的过程,其实与之前图示中的对象库部分的对象指向关系不谋而合。
我们又掌握了两个小技巧:
"git cat-file -t 哈希值"查看对象的类型
"git cat-file -p 哈希值"查看对象的内容
再免费赠送你一个命令,通过简短的哈希值获取到整个哈希值,如下:
$ git rev-parse a8319
a8319f8f9473c45a71ff86c4037a3b60a0bd1b1f
如果你坚持看到了此处,那么你可能会觉得越来越清晰了,如果你觉得越来越糊涂,不如从头看一遍,前后相互印证,也能加深理解,如果你的头脑仍然感觉很清晰,那么我们再换一个角度,来重新理解一遍上述过程,这次,我们进入".git"目录看看,看看会不会有什么新发现。
为了能够尽量减少干扰,我决定重新创建一个新的测试仓库,过程如下:
$ git init test1
Initialized empty Git repository in D:/workspace/git/test1/.git/
$ cd test1
如上所示,我创建了一个新的测试repo,并且进入了仓库目录,不过这时候仓库目录空空如也,我们先来创建一些测试数据,并且将它们保存为第一个提交吧,过程如下:
$ echo f1 > file1
$ echo f2 > file2
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
file1
file2
nothing added to commit but untracked files present (use "git add" to track)
现在,我们只将file1的修改加入暂存区,如下:
$ git add file1
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: file1
Untracked files:
(use "git add <file>..." to include in what will be committed)
file2
从上述信息可以看出,file1对应的颜色是绿色,它属于"Changes to be committed"列表,表示它准备被提交,而file2对应的颜色是红色,它属于"Untracked files"列表,表示它还没有被加入到暂存区,下次提交不会包含它的状态,也就是说,file1的状态其实已经被转化成git对象,存放在git的对象库中了,说到对象库,就能引出我们的".git"目录了,其实,git对象就存放在".git/objects/"目录中。先别急,我们先别跑的太快,先把第一个提交创建出来,如下:
$ git commit -m "commit 1"
[master (root-commit) 47b7a5c] commit 1
1 file changed, 1 insertion(+)
create mode 100644 file1
提交变更后,使用"git status"命令,信息如下:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
file2
nothing added to commit but untracked files present (use "git add" to track)
可以看到,由于file2的状态并没有添加到暂存区,所以上次提交并没有操作file2的状态,它是红色的,它仍然未被跟踪,我们先不理会它,先来看看刚才创建的提交
$ git log
commit 47b7a5c462ce4bf6f75c2a17f74f9585a74305da (HEAD -> master)
Author: lqh <lqh@zzinfor.com>
Date: Sat Oct 10 15:39:38 2020 +0800
commit 1
不错,第一个提交创建出来了,它的哈希是
47b7a5c462ce4bf6f75c2a17f74f9585a74305da 。
现在,我们可以把焦点放在".git/objects/"目录中了,既然之前说过,git对象就放在这个目录中,那么我们在这个目录中肯定能找到刚才的提交,因为一个提交在对象库中就是一个commit对象啊,现在我们在这个目录中找找,看看能不能找到它,如下:
$ find .git/objects/
.git/objects/
.git/objects/47
.git/objects/47/b7a5c462ce4bf6f75c2a17f74f9585a74305da
.git/objects/7e
.git/objects/7e/4cccb4a643b0d9cb6ac9263779147c0937d0c4
.git/objects/8e
.git/objects/8e/1e71d5ce34c01b6fe83bc5051545f2918c8c2b
.git/objects/info
.git/objects/pack
我们使用find命令查看了一下".git/objects/"目录中的内容,看看上述信息,是不是觉得有一个文件的文件路径跟刚才创建的提交的哈希码特别像,没错,git/objects/47/b7a5c462ce4bf6f75c2a17f74f9585a74305da这个文件其实就是刚才创建的提交所对应的git对象,那剩下的.git/objects/7e/4cccb4a643b0d9cb6ac9263779147c0937d0c4文件和.git/objects/8e/1e71d5ce34c01b6fe83bc5051545f2918c8c2b文件又是什么呢?使用"git cat-file"命令看看不就知道了(注意,git对象的哈希码的前两位以目录的形式存在,前两位以后的哈希码作为文件名)。
$ git cat-file -t 7e4cccb4a643b0d9cb6ac9263779147c0937d0c4
tree
$ git cat-file -t 8e1e71d5ce34c01b6fe83bc5051545f2918c8c2b
blob
从上述信息可以看出,这两个git对象分别一个tree对象和一个blob对象,应该是刚才那个提交指向的tree以及tree指向的blob,如果不信,你就用之前层层剥离的方法,从commit对象一直找下去吧,你会发现他们的哈希值是对应的。
".git/objects/"目录中存放了git对象,那么之前所描述的"索引"信息,存放在哪里了呢?索引的信息其实存放在" .git/index"文件中,我们无法直接查看这个文件内容,如果想要查看这个文件中的索引信息,可以使用如下命令:
$ git ls-files -s
100644 8e1e71d5ce34c01b6fe83bc5051545f2918c8c2b 0 file1
上述信息就是当前索引中的信息,可以看到,目前只有一个文件file1被索引记录了。
现在 ,我们继续一些其他操作,然后再来查看这些信息。
操作如下:
$ mkdir dir1
$ echo d1f3 > dir1/file3
我们创建了一个目录,并且在其中创建了新文件file3,使用"git status"命令查看状态,如下:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
dir1/
file2
nothing added to commit but untracked files present (use "git add" to track)
由于上次我们并没有将file2的状态添加到暂存区,所以,它和dir1一样都显示为未跟踪,由于只会显示当前目录的结构,所以只显示了dir1/而没有显示dir1/file3,不过当你使用"git add"命令将dir1/添加到暂存区时,dir1目录中的所有文件都会被加入到暂存区,为了方便,此时一次性将当前目录的所有变更加入到暂存区
$ git add .
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: dir1/file3
new file: file2
如上述信息所示,所有变更都已加入到暂存区,那么我们看看索引文件有没有更新
$ git ls-files -s
100644 c3b53d6ceb6ab66a0595442d70f30b33917adb18 0 dir1/file3
100644 8e1e71d5ce34c01b6fe83bc5051545f2918c8c2b 0 file1
100644 9de77c18733ab8009a956c25e28c85fe203a17d7 0 file2
可以看到,索引文件已经更新了,file2以及dir1/file3都已经存在于索引列表中了,那么对象库中肯定也已经生成了对应的blob对象了,注意,此时tree对象还没有生成在对象库中,之前说过,tree对象是在提交命令执行后才创建的,我们看看对象库中的文件,如下。
$ find .git/objects/
.git/objects/
.git/objects/4b
.git/objects/4b/3dfc8acb902ae15e32b167b009cc03330f54b1
.git/objects/7e
.git/objects/7e/4cccb4a643b0d9cb6ac9263779147c0937d0c4
.git/objects/8e
.git/objects/8e/1e71d5ce34c01b6fe83bc5051545f2918c8c2b
.git/objects/9d
.git/objects/9d/e77c18733ab8009a956c25e28c85fe203a17d7
.git/objects/c3
.git/objects/c3/b53d6ceb6ab66a0595442d70f30b33917adb18
.git/objects/info
.git/objects/pack
可以看出,对象库中的blob文件也已经生成了,现在我们要做的就是提交了
$ git commit -m "add dir1 and file2"
[master e327059] add dir1 and file2
2 files changed, 2 insertions(+)
create mode 100644 dir1/file3
create mode 100644 file2
再次查看对象库
$ find .git/objects/
.git/objects/
.git/objects/47
.git/objects/47/b7a5c462ce4bf6f75c2a17f74f9585a74305da
.git/objects/6e
.git/objects/6e/c24d16881c26dbb3c6effe7f82b7932fdbdc0d
.git/objects/7e
.git/objects/7e/4cccb4a643b0d9cb6ac9263779147c0937d0c4
.git/objects/8e
.git/objects/8e/1e71d5ce34c01b6fe83bc5051545f2918c8c2b
.git/objects/9d
.git/objects/9d/e77c18733ab8009a956c25e28c85fe203a17d7
.git/objects/c3
.git/objects/c3/b53d6ceb6ab66a0595442d70f30b33917adb18
.git/objects/c3/fddd7a9ef2818fbb7197e83d546f81cc79c1b6
.git/objects/dd
.git/objects/dd/03f30d2cac901d3e52dbc19897c88cb269805d
.git/objects/info
.git/objects/pack
你会发现多出了几个对象,多出的对象分别是新创建的commit对象,根目录的tree对象,以及dir1对应的tree对象。
其实,你应该手动单独再次修改一次file2的内容,并创建一个提交,然后再次使用上述方法,结合层层剥离的方法,自己再将上述过程重复一遍,在每操作一步时,都查看一下索引文件的内容,以及对象库中的内容有什么变化,这样,你就会更加理解上述整个过程了,我就不在文章里面啰嗦了,快动手试试吧。
最后,这里记录一个小问题,如果你跟我一样,喜欢在windows的git bash中使用vim编辑文本文件,那么,在你每次使用git add命令可能都会出现类似如下warning
$ git add .
warning: LF will be replaced by CRLF in file2.
The file will have its original line endings in your working directory
这是由于换行符冲突引起的报警,因为git bash默认使用vim作为文件编辑器,vim默认使用LF作为换行符,与linux中的换行符一致,它们都是用LF换行符,但是windows默认使用CRLF作为换行符,大多数程序员都会使用IDE或者文本编辑器来编辑文本,这些编辑器通常能够自动识别换行符,除了windows自带的记事本等文本编辑器,记事本只会使用CRLF作为换行符,由于我习惯使用vim编辑文本,所以文件中的换行符都是LF,当git检测到时,它会贴心的帮我装换一下,但是其实我并不是特别需要,因为我在bash中不会使用记事本编辑文件,所以,我们可以禁用自动转换的功能,使用如下设置,禁用自动转换换行符:
git config --global core.autocrlf false
git config --global core.autocrlf false
当然,如果你的习惯就是使用CRLF换行符的编辑器,那么目前你是不会遇到上述问题的,所以你可以根据需要选择是否进行上述设置。
Git之旅(7):分支是啥?
直到现在,我们一直都偏重概念,通常是在介绍清楚相关概念以后,才会结合相关的命令进行练习,所以,如果你同时也在看别的教程,你会发现很多不同之处,你甚至会觉得我们的进度太慢了,如果你看别的教程,在看到第7篇的时候,应该已经介绍了很多命令,但是你可能并不理解为什么要那样做,我们力求在使用命令的同时能够理解相关的原理,所以,不要着急,厚积薄发,搞定命令简直不要太轻松。
前文中,我们一直在创建提交,但是一直没有回退到过任何一个版本,主要执行的命令就是,查看状态、暂存修改、创建提交,一直在重复这三件事,这样做是为了更好的理解工作区、暂存区、提交之间的关系,不如现在,我们来尝试一下,回退到某个版本,看一看利用git进行版本回退的效果,同时,通过版本回退的操作引出"分支"的概念。
为了我们的思路能够同步,我决定重新创建一个测试仓库,一步一步的创建提交,并且回退到特定的版本,过程如下:
创建测试仓库
$ git init test_repo
Initialized empty Git repository in D:/workspace/git/test_repo/.git/
进入仓库,创建两个测试文件,f1和f2
$ cd test_repo/
$ echo 1 > f1
$ echo A > f2
如上述命令所示,f1的内容为1,f2的内容为A。
测试文件已经初始化完成了,我们来创建第一个提交吧。
$ git add .
使用"git add ."命令将当期目录中的所有变更状态加入到暂存区,然后使用如下命令创建第一个提交,注释信息为1A
$ git commit -m "1A"
[master (root-commit) 510658e] 1A
2 files changed, 2 insertions(+)
create mode 100644 f1
create mode 100644 f2
多次修改f1和f2的文件内容,并且创建对应的提交,为一会儿的回退测试做准备,过程如下,不再详细描述
$ echo 2 >> f1
$ echo B >> f2
$ git add .
$ git commit -m "2B"
[master 2fc70fe] 2B
2 files changed, 2 insertions(+)
$ echo 3 >> f1
$ echo C >> f2
$ git add .
$ git commit -m "3C"
[master aa81e63] 3C
2 files changed, 2 insertions(+)
$ echo 4 >> f1
$ echo D >> f2
$ git add .
$ git commit -m "4D"
[master 866b6de] 4D
2 files changed, 2 insertions(+)
$ echo 5 >> f1
$ echo E >> f2
$ git add .
$ git commit -m "5E"
[master 526ff66] 5E
2 files changed, 2 insertions(+)
我又一口气创建了4个提交,每次修改都对两个文件加入一行新文本,到目前为止,我们一共已经有了5个提交,最新的提交是注释信息为"5E"的提交,当前状态下,两个文件的内容如下:
$ cat f1
1
2
3
4
5
$ cat f2
A
B
C
D
E
现在,我后悔了,我想要回到"3C"时的状态,该怎么办呢?
如果想要回到"3C"时的状态,首先要找到"3C"提交的哈希码,我们先通过git log命令看看3C状态对应的哈希码吧。
$ git log --oneline
ff5bf54 (HEAD -> master) 5E
245b70c 4D
f0d2c12 3C
1b18ba7 2B
fbe40b9 1A
从上述信息可以看出,"3C"提交对应的ID是f0d2c12,好了,状态对应的哈希码已经找到了,我们可以使用如下命令,回到"3C"提交对应的状态
$ git reset --hard f0d2c12
HEAD is now at f0d2c12 3C
执行完上述命令后,再次查看工作区内两个文件的内容,如下:
$ cat f1
1
2
3
$ cat f2
A
B
C
可以看出来,我们已经回到过去了,轻松的实现了版本回退,我们只是执行了一条"git reset --hard"命令而已,我们先不纠结这条命令的参数都是什么含义,之后我们再去详细的了解它。
如果,我回到"3C"状态以后又反悔了,想要再次回到"5E"时的状态,该怎么办呢?聪明如你一定想到了,仍然使用刚才的命令啊,我们只要找到"5E"状态的哈希码,就能够通过"git reset --hard"命令再次回到"5E"的状态了,没错,查找"5E"状态的哈希码,但是当我们执行"git log"命令以后,发现"5E"状态的哈希码不见了,如下:
$ git log --oneline
f0d2c12 (HEAD -> master) 3C
1b18ba7 2B
fbe40b9 1A
由于我们之前已经使用"git reset --hard"命令回退到了"3C"时的状态,所以,"git log"命令执行后显示的最近的"commit id"只会显示到"3C",别慌,肯定还有办法能够找到我们想要的哈希码,没错,还有一条命令,那就是"git reflog"命令,执行"git reflog"命令,可以看到如下内容:
注:我们暂且不用纠结git log命令和git reflog命令的区别,因为如果想要彻底理解git reflog命令,可能还需要理解一些其他的概念,所以先往下看。
$ git reflog
f0d2c12 (HEAD -> master) HEAD@{0}: reset: moving to f0d2c12
ff5bf54 HEAD@{1}: commit: 5E
245b70c HEAD@{2}: commit: 4D
f0d2c12 (HEAD -> master) HEAD@{3}: commit: 3C
1b18ba7 HEAD@{4}: commit: 2B
fbe40b9 HEAD@{5}: commit (initial): 1A
从上述信息可以看出,"5E"对应的哈希码为"ff5bf54",所以,我们仍然可以通过这个哈希码再次回到"5E"状态对应的提交,执行如下命令即可
$ git reset --hard ff5bf54
HEAD is now at ff5bf54 5E
再次查看文件的内容,发现真的回到了"5E"的状态
$ cat f1
1
2
3
4
5
$ cat f2
A
B
C
D
E
此时,使用"git log"命令,可以看到,最近的一次提交又回到了"5E"了,如下:
$ git log --oneline
ff5bf54 (HEAD -> master) 5E
245b70c 4D
f0d2c12 3C
1b18ba7 2B
fbe40b9 1A
你看,使用git进行版本回退是不是非常的方便呢?
细心如你一定已经发现了,无论是回退操作,还是使用git log命令查看日志,都会在命令执行后的返回信息中看到一个词,这个词就是"HEAD ",那么"HEAD "是什么意思呢?你可以把"HEAD "理解成一个指针,这个指针通常指向了当前"分支"的最新的提交,你肯定会有疑问,"分支"又是个什么东西呢?为什么"HEAD "这个概念还没说明白,就又多出了一个"分支"的概念呢?不如我们先来搞明白分支是个什么东西吧。
如果想要搞明白分支的概念,不如先来看一个实际的问题,从解决问题的思路去理解一个概念,似乎更加容易一些,为了能够更加轻松的、清晰的描述问题,我又创建了一个新的测试仓库,并且创建了两个用于测试的文件,m1和m2
$ git init test_repo1
$ cd test_repo1/
$ echo 1 > m1
$ echo A > m2
$ git add -A
$ git commit -m "init file m1 and m2"
如上例所示,我创建了两个测试文件,m1和m2,假设这两个文件分别代表了两个模块,这两个模块共同组成了我想要的项目,并且假设这两个模块之间的代码在业务逻辑上是没有关系的,是相互独立的,现在,我来对这两个文件进行一些修改,模拟在实际工作中分别在两个模块上进行开发的工作,操作如下:
$ echo 2 >> m1
$ git add m1
$ git commit -m "add 2 in m1"
$ echo B >> m2
$ git add m2
$ git commit -m "add B in m2"
$ echo 3 >> m1
$ git add m1
$ git commit -m "add 3 in m1"
$ echo C >> m2
$ git add m2
$ git commit -m "add C in m2"
$ git log --oneline
13b1680 (HEAD -> master) add C in m2
8d01752 add 3 in m1
cc24ec8 add B in m2
d61675b add 2 in m1
2726907 init file m1 and m2
$ cat m1
1
2
3
$ cat m2
A
B
C
我再把上述模拟工作的过程用文字大概的描述一遍,我先是只修改了m1文件,然后针对这个修改创建了一个提交(模拟开发模块一),然后我又修改了m2文件,针对这个修改又创建了一个提交(模拟开发模块二),然后我又重复了上述过程,分别对m1和m2进行了修改,并且为各自的修改创建了提交。
假设,我现在后悔了,我想让m2文件回到"add B in m2"的状态,我该怎么办呢?没错,我们只要回退就行了,就用刚才总结的命令回退,我们来试试,执行如下命令:
$ git reset --hard cc24ec8
HEAD is now at cc24ec8 add B in m2
$ cat m2
A
B
可以发现,我们已经成功的将m2文件变成了"add B in m2"的状态,但是,你会发现一个问题,问题就是,如果你此时查看m1文件的内容,你会发现,m1文件的状态也跟着回退了,如下
$ cat m1
1
2
我们的初衷是为了让m2回到"add B in m2"的状态,但是并没有想要修改m1的状态,因为之前说过,两个模块在业务逻辑上是独立的,我们并不想为了回退某个模块,而影响另一个模块的代码。
那么我们该怎样解决这样的问题呢?如果仍然按照上面的操作方式,我们没有任何办法能够解决这个问题,因为问题的根本原因在于,针对模块一的提交和针对模块二的提交是交错的,这些提交交错在同一条'逻辑线'上,很有可能,针对模块一的某个修改就是针对模块二的某个修改的父提交,而针对模块二的某个修改又是针对模块一的某个修改的父提交,所以在这种情况下,如果你想要针对某个模块的代码进行回退,势必会影响到另外一个模块。换句话说就是,你想要回退的提交之后的提交很有可能包含其他模块的代码改动。
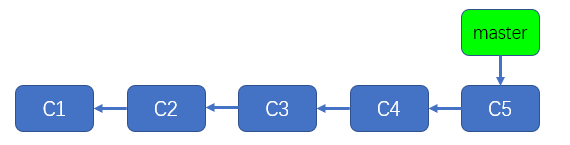
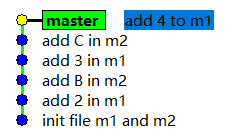
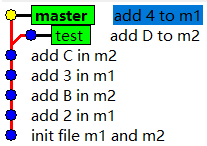
其实,造成上述问题的根本原因就在于,针对两个模块的提交混用了一条"逻辑线",你可以把这条逻辑线理解成一条所谓的"分支",默认情况下,git仓库会为我们创建一条名为master的分支,我们创建的所有提交默认都会在master分支上,这样说不够明了,不如来直观的看一下,在上例中的测试仓库中执行gitk命令,打开图形化工具,因为图形化工具能让我们更加直观的理解"分支"的概念,执行gitk命令后,如下图所示:
注:为了能显示更多的提交,我已经回退到了之前最新提交,此处省略命令

如你所见,上图中有5个提交,对于这5个提交来说 ,每个提交都是下一个提交的父提交,它们组成了一条所谓的"逻辑线",这些提交所连成的线就是所谓的分支,只不过默认情况下,所有提交会连成一条名为master的分支,从字面上理解,master分支的意思是主分支,从上图可以看出,绿色的master方形总是指向master分支上最新的提交,我们可以把上图中绿色的master方形称之为分支指针,分支指针总是指向当前分支的最新提交。
那么回到刚才的问题,上例中,当想要回退某个模块时,会影响另一个模块,这是因为默认情况下,所有提交交错在一条分支上,那么你肯定想到了解决方法,我们只要将两个模块的代码分别提交到两个分支不就能解决问题了么,没错,我们可以再创建一条分支,然后就可以将两个模块的代码分别提交到不同的分支上,这样,处于两个分支的提交在进行版本回退的操作时,就不会相互影响了,大致思路如下图所示
如上图所示,橘色代表m1相关的代码,蓝色代表m2相关的代码,我们根据当前的状态创建出一个新的分支,然后将之后的代码修改按照模块逻辑进行区分,分别提交到不同的分支上,这样就能达到我们的目的,在之后的工作中,让两个模块互不影响了。
当我们需要一个完整的项目时,则需要所有模块的代码,这时,我们只需要将两个分支合并在一起就好了,我们只要知道分支从本质上就是一些提交所连成的线,当我们需要某些提交与另一些提交之间不会相互影响时,就可以利用分支将它们分开。
当然,在实际工作中,即使使用分支,也不一定能将代码完全从业务逻辑上分开,比如,一个团队中有三个开发,A、B、C,他们为了自己的工作不影响别人,分别创建了A、B、C三条分支,但是并不代表他们不会同时修改同一个业务模块的代码,很有可能他们三个人的开发工作所对应的代码是处于同一个模块的,所以,在这种情况下,分支的作用只是为了暂时的将每个人的工作隔离开,以便不影响别人,并不是为了从业务逻辑上分开代码,但是本质上,仍然利用了分支之间的提交互不影响的特性,当然,如果A、B、C三个人同时修改了同一模块的某一段代码,当我们需要将三个人的代码整合到一起时,很有可能出现所谓的"冲突",这时候,就需要人为介入,解决冲突。
此时我们还没有完全使用过分支,所以不理解"合并分支"以及"解决冲突"这些操作是完全正常的,我们先别在意它们,不如先通过实际操作来更加具象化的认识一下分支吧。
现在,我们通过实际操作来创建一个分支,为了方便,我们继续使用上文中的示例仓库,在仓库目录中打开git bash,可以从git bash的命令提示符中看到当前工作目录处于哪个分支,如下图所示

可以看到,我们当前处于默认的分支master分支,除了在命令提示符中能够看到当前处于哪个分支以外,使用" git status"命令也可以,如下:
/d/workspace/git/test_repo1 (master)
$ git status
On branch master
nothing to commit, working tree clean
从上述返回信息可以看出,我们处于master分支。
使用"git branch"命令能够查看现在都有哪些分支
/d/workspace/git/test_repo1 (master)
$ git branch
* master
如上述命令所示,我们当前只有一个分支,这个分支的名字是master,当有多个分支时,会显示所有分支的名字,我们当前所处的分支前面会有一个"*"(星号)
使用"git branch"命令时还可以加上"-v"参数或"-vv"参数,使用"-v"参数或"-vv"参数可以查看更加详细的分支信息。
$ git branch -v
* master 13b1680 add C in m2
可以看到,目前我们处于master分支,master分支的最新的提交的哈希值为13b1680,最新的提交的注释信息为"add C in m2"
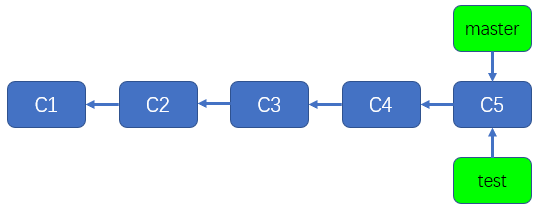
现在,我们就来创建一个新的分支,创建新分支时,默认是以当前所在的分支作为基础创建的,你可以这样理解,当我们创建新分支时,是将当前所在的分支'复制'了一份(并不是真正的复制,只是将新的分支指针指向所基于的分支对应的提交,后面会有解释,此处不用纠结),我们当前处于默认的master分支,假如我们想要创建一个用于测试的名为test的分支,那么可以使用如下命令创建
git branch test
上述命令的意思是,根据当前所在分支(master分支)创建一个名为test的分支,但是并不切换到新的分支(test分支),仍然停留在当前分支(master分支)。
执行完上述命令后,再次使用"git branch"命令查看分支信息,你会看到test分支已经被创建了,如下所示
/d/workspace/git/test_repo1 (master)
$ git branch -v
* master 13b1680 add C in m2
test 13b1680 add C in m2
从命令的返回信息可以看出来,test分支已经被创建了,由于test分支是基于master分支创建的,所以目前来说,这两条分支是完全相同的,之前说过,分支指针总是指向当前分支的最新提交,所以test分支的分支指针也会指向test分支上最新的提交,但是由于test分支是基于master分支刚刚创建完成的,所以这两条分支完全相同,test分支上最新的提交与master分支上最新的提交自然是同一个提交。
而且,从上述信息可以看出,目前我们仍然处于master分支,并没有切换到test分支,因为星号仍然处于master分支,也就是说,现在,如果在工作空间中进行改动并且创建提交,新创建的提交仍然属于master分支,因为我们并没有切换到test分支,如果想要在test分支上进行工作,则必须先切换到test分支,但是在切换分支之前,我们先使用gitk命令看一下图形化界面,看看当前的状态到底是个什么样子,执行gitk命令,可以看到当前的提交状态如下:

可以看到, test分支和master分支的分支指针同时指向了同一个提交,刚才提到过," git branch test"命令的意思是基于当前分支创建test分支,但是并不是真正的将当前分支复制一份,什么意思呢?你可以这样理解,在没有创建test分支之前,master分支如下图所示:
如上图所示,上例的测试仓库中一共有5个提交,我们用C1代表第一个提交"init file m1 and m2",用C2代表第二个提交"add 2 in m1",以此类推,每个提交都指向了自己的父提交(前文中有说过,每个提交都会指向自己的父提交,如果忘了请回顾前文),上图中绿色的master方框表示master分支的分支指针,它指向了master分支的最新提交。
当我们执行" git branch test"命令后,会基于master分支创建test分支,你可以把创建test分支的过程理解成"复制"当前的master分支,但不是真的复制,前文中一直在说,git不会像我们一样手动的创建真实的"副本",因为通过"复制操作"创建的副本总是会占用相对较多的磁盘空间,前文中git所体现出的'智慧'在这里同样适用,当我们基于master分支创建test分支时,git也并不会真正的将master分支"复制",git只会创建一个test分支指针,并且让test分支指针指向master分支对应的最新的提交,如下图所示:
聪明如你一定想到了,从"概念"上来说,目前存在两条分支,master分支和test分支,但是从"物理"上来说,其实就是5个提交连成的线,我们根据需要赋予了这条线两个含义,这两个含义就是master分支(默认创建的含义)和test分支(我们所赋予的含义),你如果阅读过前文,肯定能明白,为什么git没有将这个5个提交复制一遍,因为这时,test分支和master分支是完全一样的,所以我们只要引用这5个提交即可,没有必要的复制出5个相同的提交,也就是说,从概念上来说,现在master分支上有5个提交,test分支上同样有5个提交,并且从当前的情况来说,test分支和master分支是完全相同的,但是它们之间却又互不影响,你现在可以在test分支上随意的回退到任何一个提交,都不会影响master分支上的提交,这样说可能不太容易理解,不如先向下看。
刚才说过,如果想要使用新创建的test分支,则必须切换到新分支,那么怎样切换分支呢?使用"git checkout test"命令即可从当前分支切换到test分支,如下:
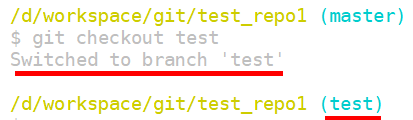
'checkout'的字面意思是'检出',也就是说,我们可以使用上述命令,从当前分支检出(切换)到其他分支,当你切换到test分支时,就表示当前工作空间中的内容已经变为test分支指针所指向的提交所对应的状态了,但是由于当前test指针和master指针指向的是同一个提交,所以即使你切换到test分支,当前工作空间中的内容也不会发生改变。
从返回信息可以看出,执行上述命令后,已经切换到test分支,在新的命令提示符中,也显示为test分支,此时,如果在工作空间进行修改并创建提交,新的提交就会属于test分支。
注:在没有创建test分支时,我们可以使用"git checkout –b test"命令同时完成创建test分支并检出test分支的操作。
好了,我们就在现在的状态下(test分支中)做一些修改,首先,先看看当前目录都有哪些文件,文件都有什么内容
/d/workspace/git/test_repo1 (test)
$ ls
m1 m2
/d/workspace/git/test_repo1 (test)
$ cat m1
1
2
3
/d/workspace/git/test_repo1 (test)
$ cat m2
A
B
C
没错,正如刚才所说,由于test分支是基于master分支刚刚创建的,所以文件目录结构和文件内容与master分支的最新状态都是一样的。
从现在开始,我们规定,m1文件的修改以后都在master分支上进行,m2文件的修改以后都在test分支上进行,这样做为了模拟不同模块在不同分支上开发的那种场景,以便解决上文中提出的模块之间的提交互相影响的问题,那么,我们当前处于test分支,我现在修改一下m2文件(模拟一下在test分支上开发模块二的场景),并将修改创建成新的提交。
/d/workspace/git/test_repo1 (test)
$ echo D >> m2
/d/workspace/git/test_repo1 (test)
$ cat m2
A
B
C
D
/d/workspace/git/test_repo1 (test)
$ git add m2
/d/workspace/git/test_repo1 (test)
$ git commit -m "add D to m2"
[test 30d80b0] add D to m2
1 file changed, 1 insertion(+)
从上述信息可以看出,我们在test分支上创建的最新的提交的哈希码为30d80b0
此时,使用gitk命令打开图形化界面,如下
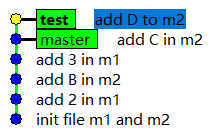
可以看到,新的提交已经属于test分支了,但是由于我们并没有修改master分支,所以master分支的最新提交仍然是上一个commit,以目前的状态来看,两个分支的关系可能并不是特别明了,我们换一种方式来解释一下,当前状态如下图所示。
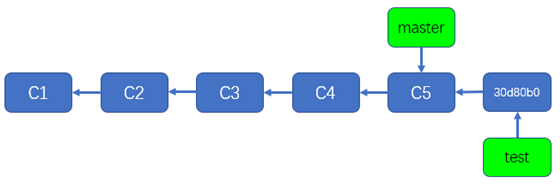
现在,master分支和test分支已经不一样了,目前来说,master分支上只存在5个提交,而test分支上存在6个提交,因为从master分支的分支指针开始,沿着"箭头"的方向(不能与箭头的指向相逆),能找到5个提交,而从test分支的分支指针开始,沿着"箭头"的方向,能找到6个提交,所以,当前的状态来讲,master分支由5个提交组成,test分支由6个提交组成。
那么现在,我们切换回master分支,并且查看一下m2文件的内容,(注意,切换回master分支就表示当前的工作空间中的内容会变成master分支指针所指向的提交所对应的状态),操作如下:
/d/workspace/git/test_repo1 (test)
$ git checkout master
Switched to branch 'master'
/d/workspace/git/test_repo1 (master)
$ cat m2
A
B
C
你会发现,master分支中的m2文件中并没有字母D,因为刚才对m2添加字母D的操作对应的提交是属于test分支上的,所以对master分支上的文件内容并没有任何影响。
当前,我们处于master分支,那么我们来修改一下m1文件(模拟一下在master分支上开发模块一的场景),过程如下:
/d/workspace/git/test_repo1 (master)
$ cat m1
1
2
3
/d/workspace/git/test_repo1 (master)
$ echo 4 >> m1
/d/workspace/git/test_repo1 (master)
$ git add m1
/d/workspace/git/test_repo1 (master)
$ git commit -m "add 4 to m1"
[master 7406a10] add 4 to m1
1 file changed, 1 insertion(+)
这个在master分支上创建的最新的提交的哈希码为7406a10
完成上述操作,再次打开gitk图形化,你会发现如下图所示
(注:后面会有解释为什么下图中看不到test分支)
你可能会有疑问,为什么没有看到test分支的分支指针,只能看到master分支,这是因为默认的视图在上述情况下不会显示所有分支,我们可以新建一个适合自己使用的视图,步骤如下:
点击gitk的View菜单,选择New view新建视图
你可以根据自己的喜好给视图取个名字,我写入的名字叫allbranch,勾选Rememer this view,以便这个视图可以被保存,下次还可以从View菜单选择这个视图,勾选下图中红框中的选项,以便所有我们需要的信息都会显示
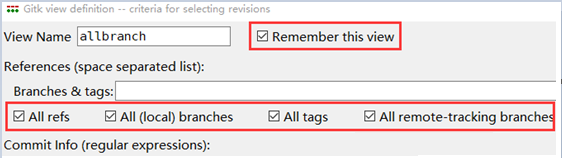
按照上图设置后,点击下方的OK按钮,点击后,gitk即会使用我们创建的视图显示分支,于是,你会看到gitk如下图所示:
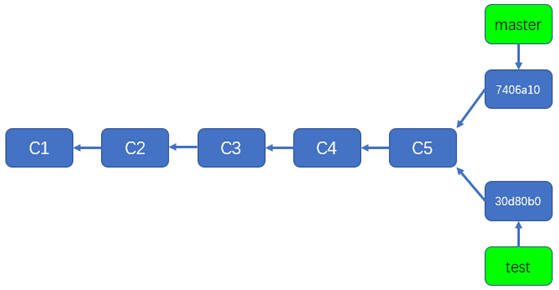
如上所示,你会看到一个'分叉',能同时看到master分支和test分支,'分叉点'是'add C in m2'对应的提交,分叉点以后,master分支和test分支分别有一个新的提交,这两个提交分别属于master分支和test分支,虽然这两个提交属于不同的分支,但是它们有同一个父提交,就是'add C in m2'对应的提交。
对于上例来说,分叉点之前的提交仍然可以理解成是两个模块的逻辑交错在一条逻辑线的提交,因为无论对于master分支来说,还是对于test分支来说,这两个模块的提交都是交错的存在于master分支上或者说交错的存在于test分支上,分叉点之后的提交才是我们人为的、按照所谓的'模块逻辑'区分隔离在不同分支上的提交。
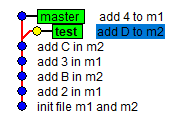
我们换一种方式,来描述一下上例的状态,如下图所示:
当前我们处于master分支,你在master分支查看m2文件的内容,并不能看到字母D,同理,如果你切换回test分支,在test分支中查看m1文件的内容,也并不能看到数字4,这时,就可以让我们更加明显的体会到分支的作用了,以后,所有m1的修改都切换到master分支上进行并创建提交,所有m2的修改都切换到test分支上进行并提交,这样,就能将这些提交隔开在两个分支上,直到你想将两个模块的代码合并到一起时,利用分支的合并就可以了,但是分支的合并操作我们留在后文中总结,现在不急。
现在,你可以自己动手进行一些实验,按照我们刚才的规定,修改m1文件并在master分支上创建一些提交,然后再切换到test分支,修改m2文件并创建一些提交,(具体的操作步骤此处就省略了,你可以自己动手尝试一下),这样听上去似乎比较麻烦,但是在实际的工作中,你通常会检出某一个特定的分支,然后在这条分支上工作一段时间,在特定的分支上完成某项工作,并不会过于频繁的切换分支,上例之所以要频换的切换分支,只是为了展示出分支的使用方式和特性。
现在,我们来扩展一下,如果此时,我们想要在test分支上,回退到" add 2 in m1"时的状态,该怎么做呢?具体操作我就不在赘述了,聪明如你肯定已经胸有成竹了,等你操作完成后,记得用gitk看看两个分支的样子,然后再切换到不同的分支上,看看所有文件的内容,你就会更加强烈的体会到git的强大了。
再次声明一下,上例一直拿'分开代码之间的逻辑'来举例并不代表分支的作用仅仅是为了'分开代码之间的逻辑',之所以这样举例,是为了利用分支之间的提交互不影响的特性,所以,只要可以利用这个特性解决的问题,都可以使用分支,而且分支的命名也是根据你的需要命名的,只不过,经过不断的实践,人们往往会按照最佳实践中的方式去使用分支,所以说,上例只是为了方便快速的让我们理解分支的作用而已,我们现在不用考虑那么多,先理解分支的概念就好。
说到这里,我觉得我们肯定已经对分支的概念有了初步的认识,这是重要的一大步,因为在git中,是鼓励我们使用分支的,由于git的'智慧',我们在git中创建分支的成本其实相对较低(与其他版本管理软件相比),所以,理解分支,学会使用分支,能让我们更好的使用git进行版本管理的工作。
Git之旅(8):HEAD是啥?
为了方便,我仍然使用之前的测试仓库进行测试,你也可以随意的创建一个用于测试的git仓库,然后创建几条分支,以便测试时使用。
我们先来回顾一下前文中测试仓库的状态,如下:
注:下图中使用了前文中创建的allbranch视图
如上图所示,我们现在有两个分支,master分支和test分支,从上图可以看出,目前我们处于黄色的提交,也就是test分支的"add D to m2",如果我们想要切换回master分支,则可以使用前文中总结的如下命令
/d/workspace/git/test_repo1 (test)
$ git checkout master
Switched to branch 'master'
/d/workspace/git/test_repo1 (master)
$
如上述信息所示,我们已经从test分支切换到了master分支。
假设,我们现在关闭git bash和工作目录,当我们下次再次进入工作目录并且打开git bash时,仍然会显示为当前处于master分支,因为我们上次关闭工作目录之前,已经切换到了master分支,当然,如果你之前处于test分支,那么当你再次打开工作空间,仍然会显示你处于test分支。
那么问题来了,git是怎么知道我们当前该处于哪个分支呢?
git其实就是靠HEAD知道我们该处于哪个分支的,你可以把HEAD理解成一个指针,HEAD指针通常会指向一个分支(或者说指向一个分支指针),分支和分支指针的概念我们在前文中已经说明过,此处不再赘述,你可以把HEAD也理解成一个指针,这个指针通常指向一个分支指针,这样说不太直观,不如看下图(仍然在前文的图片的基础上进行修改):
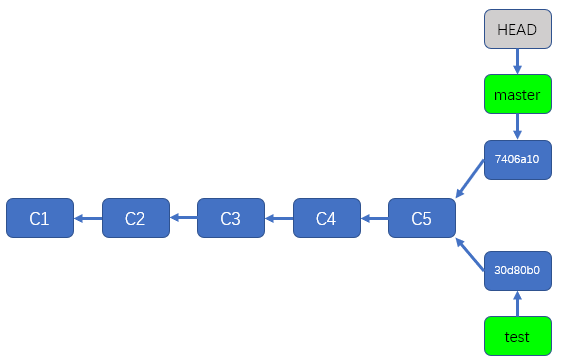
如上图所示,由于我们当前处于master分支,所以,HEAD这个指针指向了master分支指针,如果我们现在检出test分支,那么HEAD指针就会指向test指针,也就是说,当我们从master分支检出到test分支时,HEAD指针会由上图中的状态变成下图中的状态:
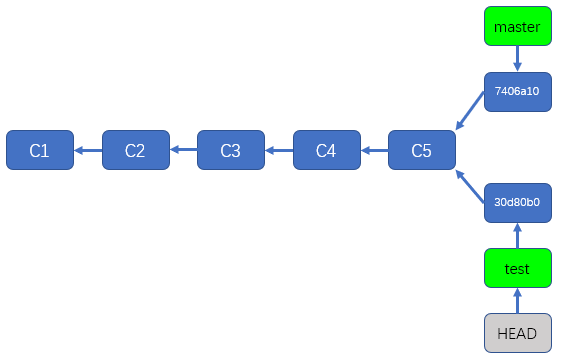
所以说,git只要找到HEAD,就能找到我们当前所处的分支(因为我们在切换分支时,会将HEAD指向所在的分支)。
我们可以直观的查看当前仓库的.git目录中的HEAD文件的内容,你会发现,其实.git/HEAD文件的内容就是HEAD指针所指向的分支,如下所示:
/d/workspace/git/test_repo1 (master)
$ cat .git/HEAD
ref: refs/heads/master
从上述返回信息可以看出,当前HEAD指针指向了另一个文件,这个文件就是.git/refs/heads/master,那么我们顺藤摸瓜,看看.git/refs/heads/master这个文件的文件内容
/d/workspace/git/test_repo1 (master)
$ cat .git/refs/heads/master
7406a10efcc169bbab17827aeda189aa20376f7f
可以看到,这个文件的内容是一串哈希码,而这个哈希码正是master分支上最新的提交所对应的哈希码。
聪明如你,肯定已经看出来了,.git/HEAD文件和.git/refs/heads/master文件不正是上图中的HEAD指针和master分支指针么,没错,就是这样的,只不过,在Git中,这些代表了上图中"指针"的文件还有另外一个名字,它们被称之为"引用" (references 或者 refs),其实都是一样的东西,不用纠结于它们的名字。
为了证明我们的想法,我们切换几次分支, 看看.git/HEAD文件内容的变化
/d/workspace/git/test_repo1 (master)
$ git checkout test
Switched to branch 'test'
/d/workspace/git/test_repo1 (test)
$ cat .git/HEAD
ref: refs/heads/test
/d/workspace/git/test_repo1 (test)
$ git checkout master
Switched to branch 'master'
/d/workspace/git/test_repo1 (master)
$ cat .git/HEAD
ref: refs/heads/master
嗯嗯,看来是没错了,跟我们想的一样,HEAD指针通常指向我们所在的分支(的分支指针)。
前文中说过,当我们在某个分支上创建新的提交时,分支指针总是会指向当前分支的最新提交。
而刚才又说过,HEAD指针通常会指向当前所在分支的分支指针。
那么,结合上述两点,我们可以得出如下结论:
HEAD指针 --------> 分支指针 --------> 最新提交
也就是说,通常情况下,HEAD指针总是通过分支指针,间接的指向了当前分支的最新提交。
单纯的靠上述文字描述可能不够直观,不如通过实际的操作来验证一下,操作如下:
首先,我们切换回test分支,看看当前HEAD指针和分支指针的指向,如下:
/d/workspace/git/test_repo1 (master)
$ git checkout test
Switched to branch 'test'
/d/workspace/git/test_repo1 (test)
$ cat .git/HEAD
ref: refs/heads/test
/d/workspace/git/test_repo1 (test)
$ cat .git/refs/heads/test
30d80b030d1a960bd90f020be2a3efb657c978e9
从上述命令可以看出,切换到test分支以后,HEAD指针指向了test分支指针,而test分支指针指向了30d80b0这个提交,如下图所示
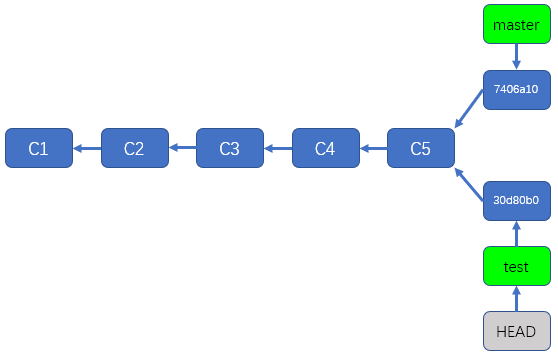
那么现在,我们来尝试在test分支上创建一个新的提交,看看HEAD指针和test分支指针会有哪些变化,操作如下:
/d/workspace/git/test_repo1 (test)
$ echo E >> m2
/d/workspace/git/test_repo1 (test)
$ git add m2
/d/workspace/git/test_repo1 (test)
$ git commit -m "add E to m2"
[test 35cff8c] add E to m2
1 file changed, 1 insertion(+)
/d/workspace/git/test_repo1 (test)
$ cat .git/HEAD
ref: refs/heads/test
/d/workspace/git/test_repo1 (test)
$ cat .git/refs/heads/test
35cff8cabb71d553ab1abceaf33fa5a046a17bdb
如上所示,我们在test分支上创建了一个新的提交35cff8c,然后查看了.git/HEAD,发现HEAD指针仍然指向了test分支指针,而test分支指针已经指向了最新创建的提交,也就是35cff8c,如下图所示:
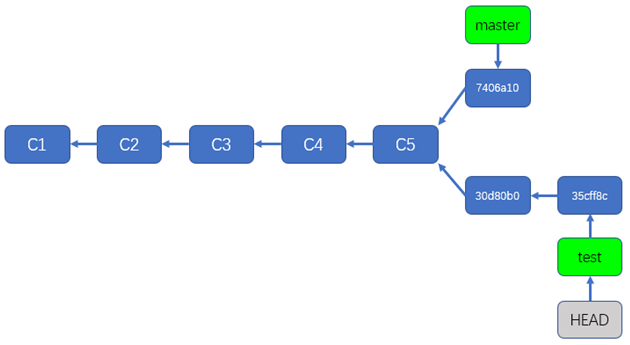
所以说,通常情况下,HEAD指针总是指向了当前分支的最新提交(通过分支指针间接的指向)。
Git之旅(9):比较差异
我们一直在总结git中的各种概念,现在,我们可以换一个方向,从一些简单的使用场景出发,了解一些新的Git命令,不过我们前面的努力并没有白费,因为站在前文概念的基础上,能够很快的理解这些命令。
现在主要来看看怎样比较差异,比较差异是我们在使用git的过程中经常会遇到的场景,我们边做边聊,为了方便演示,重新创建一个git仓库,并且创建两个测试文件,命令如下:
$ git init test_repo
$ cd test_repo
$ echo 1 >> test1
$ echo 2 >> test1
$ echo 3 >> test1
$ echo a >> test2
$ echo b >> test2
$ echo c >> test2
$ git add test1 test2
$ git commit -m "init test file"
我创建了两个测试文件,test1和test2,然后将这两个文件添加到了暂存区,最后创建了一个提交,也就是说,最新的提交中保存了test1文件和test2文件的当前的状态。
目前test1和test2的文件内容如下:
$ cat test1
1
2
3
$ cat test2
a
b
c
现在,我想要修改一下这两个文件,我想把test1文件的第2行删除,然后再添加一行,我想把test2文件的最后一行的'c'改成'cc',修改后的结果如下:
$ cat test1
1
3
new
$ cat test2
a
b
cc
上述修改的操作其实是在我的工作目录中进行的,上述操作完成后,我们并没有使用git add命令将修改添加到暂存区,更没有创建提交,所以说,当前工作区的test1文件和test2文件的内容与暂存区和提交中的内容是不同的,那么我们怎样对比这种不同呢?很简单,我们只要使用git diff命令就能够进行差异比较了,比如,我想比较一下,当前的工作目录和暂存区中都有哪些差异呢?则可以直接使用git diff命令进行对比,示例如下:
注:最好在你的命令窗口中键入同样的命令,有语法着色的情况下更加直观
$ git diff
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..278314e 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,3 @@
a
b
-c
+cc
执行git diff命令后,返回信息如上,可以看到,test1文件中的第二行被删除了,因为"2"前面有一个减号,并且,添加了新的一行,新行的内容为"new",因为"new"前面有一个加号,test2文件中的差异也被显示了出来,我们把test2文件中的第三行的'c'改成了'cc',对于git来说,git认为我们把'c'这一行删除了,然后又在原位置添加了新的一行'cc',可以看出,当我们使用git diff命令时,git会将工作区与暂存区中的所有文件差异一次性的全部显示出来,如果我们只想查看某个特定文件在这两个区域的差异,也可以指定要查看的文件,比如,我们只想看看test1文件在工作区和暂存区是否存在差异,只需要执行如下命令即可:
$ git diff -- test1
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
上例中的'--'后面可以跟随多个文件路径,每个文件路径用空格隔开,上述命令中我们只指定了test1文件的文件路径。
由于我们修改文件以后并没有暂存这些修改,更没有创建提交,所以,目前来说,暂存区和提交中的文件内容是相同的,也就是说,"暂存区和提交中指向的文件" 与 "工作区中的文件" 之间的差异是相同的,那么,怎样查看工作区和提交中的文件差异呢?如果想要查看工作区和最新提交之间的差异,则可以使用如下命令查看:
$ git diff HEAD
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..278314e 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,3 @@
a
b
-c
+cc
没错,使用"git diff HEAD"命令即可查看工作区与当前分支最新的提交之间的差异,还记得上一篇文章中我们总结的HEAD指针么?前一篇文章中我们总结过,通常情况下,HEAD指针总是间接的指向了当前所在分支的最新提交,所以,你可以把"git diff HEAD"命令中的HEAD理解成当前所在分支的最新提交的别名,聪明如你一定想到了,我能不能把HEAD替换成当前分支最新提交的哈希码呢?当然可以,示例如下(下例命令中的哈希码就是最新提交的hash值):
$ git diff a63d5b2f38dffb0c0e749a4c49a924490e23a190
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..278314e 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,3 @@
a
b
-c
+cc
可以看到,上述命令返回的结果与"git diff HEAD"命令所返回的结果是完全相同的,你可以无差别的使用这两种方式去查看当前的工作区与最新提交之间的差异,之前说过,修改操作完成后我们并没有暂存修改,更没有机会提交修改,所以,以目前的状态来说,使用"git diff命令"和使用"git diff HEAD命令"查看到的差异信息是完全一样的,因为以目前的情况来说,暂存区和提交中的状态是完全相同的,小结一下:
我们可以使用下图中的命令,比较"工作区和暂存区的差异"以及"工作区和提交中的差异"
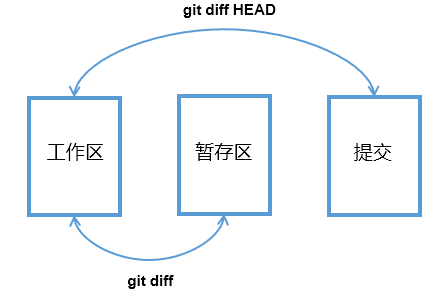
刚才我们只是进行了修改操作,没有进行任何暂存和提交,现在,我们来将刚才的修改添加到暂存区,执行如下命令:
$ git add -A
我使用上述命令,一次性将所有文件的所有变更都进行了暂存,从目前状态来看,工作区中的文件状态已经和暂存区的文件状态相同了,因为我已经把所有变更都暂存了,所以,此时再次使用"git diff"命令查看工作区和暂存区的文件差异,则不会显示任何内容,因为此时这两个区域没有差异,但是如果我执行"git diff HEAD"命令,仍然可以查看到工作区和提交之间的差异。
如果此时,我再次在工作区进行一些变更,会怎样呢?
我们来试试,我们尝试着在test2文件中添加一行,命令如下:
$ cat test2
a
b
cc
$ echo dd >> test2
$ cat test2
a
b
cc
dd
我们在test2命令中添加了一行文本为"dd"的新行。
此时,再次查看工作区和另外两个区域的差异,如下:
查看工作区和暂存区的差异
$ git diff
diff --git a/test2 b/test2
index 278314e..e165bb5 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,4 @@
a
b
cc
+dd
查看工作区和最新提交的差异
$ git diff HEAD
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..e165bb5 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,4 @@
a
b
-c
+cc
+dd
没错,我们通过 "git diff" 和 "git diff HEAD" 命令已经可以清楚的查看到了工作区和另外两个逻辑区域的差异了,你可能会问,如果在这个时候,我想要查看暂存区和最新提交之间的差异,该怎样查看呢?很简单,使用"git diff --cached"命令即可查看,示例如下:
$ git diff --cached
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..278314e 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,3 @@
a
b
-c
+cc
由于最新的修改(在test2中添加"dd"文本的操作)还没有暂存到暂存区,所以,当我们查看暂存区和最新提交之间的差异时,是看不到最新添加的"dd"的,因为在此时,暂存区和提交中都没有"dd"这一行,目前来说,"dd"这一行只存在于工作区的test2文件中。
也就是说,我们可以通过下图中的命令,比较各个"区域"之间的差异。
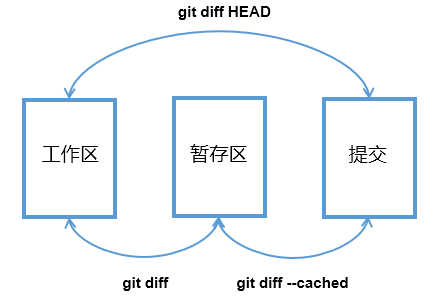
此时,我们执行"git status"命令,查看当前仓库的状态,如下
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: test1
modified: test2
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: test2
可以看到,第一次的修改操作已经添加到了暂存区,但是第二次的修改操作(在test2中添加"dd"的操作)还没有被暂存区,为了方便演示,我先将最新的修改暂存,然后一次性的将所有修改全部提交,命令如下:
$ git add test2
你可以在执行上述命令后,再次对比一下各个区域的差异,此处为了方便进行后面的演示,将所有修改一次性提交
$ git commit -m "test"
我们已经将之前所有的变更操作提交了,到目前为止,我们的仓库中已经保存了两个状态,也就是说,当前的git仓库中一共有两个提交,我们能不能对比一下这两个提交之间的差异呢?当然能了,同样使用git diff命令就能完成,首先,我们来查看一下当前的提交历史,如下:
$ git log --oneline
aafbaa8 (HEAD -> master) test
a63d5b2 init test file
如你所见,我们已经创建了两个提交,第一个提交是'a63d5b2',第二个提交是'aafbaa8',如果我想要对比这两个提交之间的差异,则可以使用如下命令:
$ git diff a63d5b2 aafbaa8
diff --git a/test1 b/test1
index 01e79c3..397b006 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,3 @@
1
-2
3
+new
diff --git a/test2 b/test2
index de98044..e165bb5 100644
--- a/test2
+++ b/test2
@@ -1,3 +1,4 @@
a
b
-c
+cc
+dd
如你所见,执行上述命令后,会显示出第二个提交相对于第一个提交之间的文件内容差异。
上文中说过,可以使用"HEAD"代指最新的提交,所以,上述命令可以改成如下命令,它们的效果是一样的。
$ git diff a63d5b2 HEAD
其实,我们还有更简便的方法,比如,我们可以把上述命令改成如下命令:
$ git diff HEAD~ HEAD
上述命令中的"HEAD"代表最新的提交,上述命令中的"HEAD~"代表最新提交的前一个提交,由于我们只有两个提交,所以,"HEAD"代表最新的提交(即 aafbaa8 ),"HEAD~ "代表最新提交的前一个提交(即 a63d5b2 ),没错,这是GIT中的一种简易写法,当我们想要操作git中的"最新提交"或者"最新提交之前的某个提交"时,可以使用这种简易写法,这种简易写法的规则如下:
HEAD 表示当前分支的最新提交
HEAD~ 表示当前分支的最新提交的前一个提交(即最新的第二个提交,也就是最新提交的父提交)
HEAD~~ 表示当前分支的最新提交的前前提交(即最新的第三个提交,也就是最新提交的祖父提交)
HEAD~~~~ 表示当前分支的最新提交的前前前提交(即最新的第四个提交,也就是最新提交的曾祖父提交)
那么,如果我想要表示最新的第五个提交,难道必须写够4个 ~ 符号才行么?就没有更简单的表示方法么?当然有了,"HEAD"可以写成"HEAD~4",它们两个是等效的,它们都表示最新的第5个提交。
HEAD~等效于HEAD~3
HEAD等效于HEAD~2
HEAD~等效于HEAD~1
HEAD等效于HEAD~0
上述简易的写法被称作"相对提交名",我们可以使用相对提交名来快速的定位(或者代指)最新的几个提交,这样做的方便之处就在于我们不用通过"git log"命令查看最近的几个提交的哈希值,就可以直接通过相对提交名快速的操作最新的几个提交了,还是很方便的。
注:你可能还看到过类似"HEAD^"写法的相对提交名,这样的相对提交名在提交有多个直系父提交时比较常用,由于我们还没有总结怎样merge分支,所以暂时不用纠结于这几种写法。
其实,我们还可以反过来操作,利用相对提交名获取到对应提交的哈希码,只要借助"git rev-parse"命令即可。
比如,获取到最新的第二个提交的哈希码
$ git rev-parse HEAD~
a63d5b2f38dffb0c0e749a4c49a924490e23a190
你还记得"git rev-parse"命令吗,我们在前文中用过这个命令,此命令可以通过哈希码的缩写获取到完整的哈希码,比如如下命令:
$ git rev-parse a63d5b
a63d5b2f38dffb0c0e749a4c49a924490e23a190
"git rev-parse"命令不仅能通过相对提交名和哈希码缩写获取到完整的哈希码,还可以通过分支名或者标签名获取到对应提交的哈希码,比如获取master分支上最新提交的哈希码
$ git rev-parse master
aafbaa85ae9f11a5875ba0b66daa76e9afb13c35
你可以将上述命令master分支名换成任何一个别的分支的分支名,比如,test分支、develop分支、任何一个其他分支的名字都可以,而且你不用切换到对应的分支上,就能够获取到对应分支上的最新提交的哈希码。
我们似乎跑题了,现在,我们把话题扯回到"git diff"命令上。
我们刚才用"git diff a63d5b2 aafbaa8"命令比较了这两个提交,除了这种写法可以比较两个commit,如下写法也是等效的:
$ git diff a63d5b2..aafbaa8
没错,我们无非是在两个"commit ID"之间添加了两个点".."而已,这种语法也可以比较两个commit之间的差异,当我们使用这种语法时,可以省略任意一边的哈希值,省略的那边的哈希值会被'HEAD'替代,也就是说,如下两条命令是等效的。
$ git diff a63d5b2..
$ git diff a63d5b2..HEAD
到目前为止,我们都是在新创建的测试仓库的master分支上做测试的,现在我们来创建一个新分支,看看在多分支下进行差异对比会不会有什么新发现。
首选,创建一个新的test分支,命令如下:
$ git checkout -b test
Switched to a new branch 'test'
通过上述命令,我们基于master分支创建了新的test分支,并且切换到了test分支上。
现在,我们分别在test分支和master分支上做一些修改,并且创建提交,然后再使用"git diff"命令进行一些比较差异的测试。
首先,在test分支上做一些变更,并且创建提交,操作如下:
/d/workspace/git/test_repo (test)
$ ls
test1 test2
/d/workspace/git/test_repo (test)
$ echo "test branch has been created" > test3
/d/workspace/git/test_repo (test)
$ git add test3
/d/workspace/git/test_repo (test)
$ git commit -m "add new file test3 in test branch"
[test b5543f1] add new file test3 in test branch
1 file changed, 1 insertion(+)
create mode 100644 test3
然后,我们切换到master分支,做一些变更,并且创建提交,操作如下:
/d/workspace/git/test_repo (test)
$ git checkout master
Switched to branch 'master'
/d/workspace/git/test_repo (master)
$ ls
test1 test2
/d/workspace/git/test_repo (master)
$ cat test1
1
3
new
/d/workspace/git/test_repo (master)
$ echo 'New changes in the master branch' >> test1
/d/workspace/git/test_repo (master)
$ cat test1
1
3
new
New changes in the master branch
/d/workspace/git/test_repo (master)
$ git add test1
/d/workspace/git/test_repo (master)
$ git commit -m "New changes in the master branch"
[master ba4b75f] New changes in the master branch
1 file changed, 1 insertion(+)
上例中,我们在master分支的test1分支中添加了一行新行,新行的内容为"New changes in the master branch",并且为此修改操作创建了提交。
此时,使用"gitk --all"命令查看分支,如下图所示

现在我们已经有了两个分支,master分支和test分支,并且两个分支上都有了属于各自分支的提交,那么此时,我们来尝试使用"git diff"命令来尝试对比一下这两个分支吧,命令如下:
/d/workspace/git/test_repo (master)
$ git diff test master
diff --git a/test1 b/test1
index 397b006..7e5632c 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,4 @@
1
3
new
+New changes in the master branch
diff --git a/test3 b/test3
deleted file mode 100644
index 2116a15..0000000
--- a/test3
+++ /dev/null
@@ -1 +0,0 @@
-test branch has been created
上例中,我们尝试使用"git diff test master"命令对比"两个分支"的差异,其实,"git diff test master"命令并没有对比这两个分支的差异,而是对比了这两个分支上最新提交之间的差异,也就是说,上述命令的作用仍然是两个提交的对比,是master分支上最新的提交与test分支上最新的提交之间的差异比较,我们完全可以将上述命令中的test换成test分支上最新提交的哈希码,将上述命令中的master换成master分支上最新提交的哈希码,我们得到的结果将和上述命令完全相同,不信?我们来试试,测试如下
首先,我们通过git log命令找到test分支和master分支上的最新的提交的哈希码,如下
/d/workspace/git/test_repo (master)
$ git log --oneline --graph --all
* ba4b75f (HEAD -> master) New changes in the master branch
| * b5543f1 (test) add new file test3 in test branch
|/
* aafbaa8 test
* a63d5b2 init test file
从上述命令可以看出,test分支上最新提交的哈希码为b5543f1,master分支上最新提交的哈希码为ba4b75f ,然后,我们将"git diff test master"命令中的test和master分别换成这两个哈希码,操作如下:
/d/workspace/git/test_repo (master)
$ git diff b5543f1 ba4b75f
diff --git a/test1 b/test1
index 397b006..7e5632c 100644
--- a/test1
+++ b/test1
@@ -1,3 +1,4 @@
1
3
new
+New changes in the master branch
diff --git a/test3 b/test3
deleted file mode 100644
index 2116a15..0000000
--- a/test3
+++ /dev/null
@@ -1 +0,0 @@
-test branch has been created
可以看到,上述命令的返回结果与"git diff test master"命令的返回结果完全相同,也就是说,虽然"git diff test master"命令中写的是分支名,但是"分支名"对应的其实是"分支上最新的提交"。
所以说,我们也可以把上述命令写成如下命令
$ git diff test..master
它们都是等效的。
小结:
此处把常用的git diff命令总结一下,以便回顾
git diff
比较工作区和暂存区
git diff HEAD
比较工作区和当前分支最新的提交,你可以把HEAD换成别的分支的名字,比如test分支,"git diff test"表示比较当前工作区和test分支最新的提交之间的差异,也可以把HEAD替换成任何一个commit的ID,表示比较当前工作区和对应提交之间的差异。
git diff --cached
比较暂存区和当前分支最新的提交
上述命令都是比较所有文件的差异,如果想要指定文件,可以使用"--"指定文件的路径,文件路径可以有多个,用空格隔开。
git diff -- file1
git diff -- ./file1
只比较工作区和暂存区中file1文件的差异
git diff -- file1 file2
只比较工作区和暂存区中file1以及file2文件的差异
git diff -- dir1/d1/f1
只比较工作区和暂存区中dir1/d1/f1文件的差异
git diff -- dir1/
只比较工作区和暂存区中dir1目录中所有文件的差异
git diff HEAD -- ./file1
只比较工作区和当前分支最新的提交中file1文件的差异,HEAD可以替换成分支名或者commitID
git diff testbranch -- ./file1
只比较工作区和testbranch分支最新的提交中file1文件的差异
git diff --cached testbranch
比较暂存区和testbranch分支最新的提交
git diff --cached testbranch --./file1
只比较暂存区和testbranch分支最新的提交中file1文件的差异
git diff HEAD~ HEAD
比较当前分支中最新的两个提交之间的差异
git diff HEAD~ HEAD -- file1
比较当前分支中最新的两个提交中的file1文件的差异
git diff commitID1 commitID2
比较两个commit之间的差异
git diff commitID1..commitID2
同上,比较两个commit之间的差异,两个命令等效
git diff branch1 branch2
比较两个分支上最新提交之间的差异
git diff branch1..branch2
同上,比较两个分支上最新提交之间的差异,两个命令等效
Git之旅(10):后悔了,怎么办?
人都是会后悔的,你我都不能例外。
在使用Git进行版本管理的过程中,我们也会经常后悔的,比如,我写了一些代码,做了一些修改,为了能将这些修改创建为提交,我先进行了暂存操作,但是没有立即创建提交,也就是说,这些修改从工作区同步到了暂存区,以便将来能够创建提交,但是过了一会儿,我后悔了,我觉得这些修改并不适合用来创建下次的提交,我该怎么办呢?这些修改已经存在于工作区和暂存区了,我现在想要保留工作区的修改,但是不想让这些修改同时存在于暂存区,也就是说,我想要撤销暂存区中的变更,我该怎么办呢?
此时,我们只需要借助一条git命令就能达到我们的目的,这条命令就是"git reset HEAD",看到这条命令,是不是觉得特别熟悉,没错,前文中我们粗略的使用过"git reset"命令,但是并没有详细的介绍它,这篇文章我们就来仔细的聊聊"git reset"命令。
刚才说过,"git reset HEAD"命令可以帮助我们把暂存区恢复到未暂存任何工作区修改的状态(即与最新的commit的状态保持一致),那么现在我们就来通过实际的操作来演示一遍。
首先,创建一个用于演示的测试仓库,然后创建两个用来测试的文件,最后初始化第一个提交,命令如下:
$ git init test_repo
Initialized empty Git repository in D:/workspace/git/test_repo/.git/
$ cd test_repo/
$ echo 'test file1' > f1
$ echo 'test file2' > f2
$ git add -A
$ git commit -m 'init, add f1 and f2'
[master (root-commit) 1a09207] init, add f1 and f2
2 files changed, 2 insertions(+)
create mode 100644 f1
create mode 100644 f2
$ git log --oneline
1a09207 (HEAD -> master) init, add f1 and f2
如上述命令所示,我们创建了两个测试文件,f1和f2,并且创建了第一个提交,第一个提交的哈希码为"1a09207"。
准备工作完毕,现在我们来模拟一遍文章开头描述的场景,命令如下:
首先,在两个测试文件中各自添加一行新行,模拟修改操作,如下:
$ echo 'The second line in the f1 file' >> f1
$ echo 'The second line in the f2 file' >> f2
然后查看git仓库状态,发现有两个文件变更没有暂存,如下:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: f1
modified: f2
no changes added to commit (use "git add" and/or "git commit -a")
看工作区和暂存区的差异,可以看到新增的两行
$ git diff
diff --git a/f1 b/f1
index d9e310a..2041f47 100644
--- a/f1
+++ b/f1
@@ -1 +1,2 @@
test file1
+The second line in the f1 file
diff --git a/f2 b/f2
index d15d3b2..4d9f2f1 100644
--- a/f2
+++ b/f2
@@ -1 +1,2 @@
test file2
+The second line in the f2 file
将所有变更添加到暂存区
$ git add -A
再次查看仓库状态,发现两个测试文件的变更状态已经同步到暂存区,我们随时可以根据这些变更创建新的提交。
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: f1
modified: f2
再次对比差异,可以看出工作区和暂存区已经没有任何差异。
$ git diff
刚才我将变更添加到暂存区是因为我觉的这些变更适合成为下一次的提交,但是我现在后悔了,我想要让这些变更从暂存区消失,我想要暂存区回到之前没有这些变更的状态,换句话说就是,我想要暂存区中的状态跟当前分支中最新提交中的状态一样,上文已经说过,我可以使用"git reset HEAD"命令来实现,我们来试试,如下:
$ git reset HEAD
Unstaged changes after reset:
M f1
M f2
执行上述命令后,可以从返回信息中看出,f1和f2的修改已经从暂存区移除了。
那么现在,我们来使用"git status"命令来看一下当前仓库的状态,如下:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: f1
modified: f2
no changes added to commit (use "git add" and/or "git commit -a")
从返回信息可以看出,关于f1和f2两个文件的修改操作已经变成了未暂存的状态。(在你的命令窗口中,f1和f2那两行文字应该是红色的,表示未暂存)
也就是说,刚才的reset命令已经生效了,这条命令成功的将已经同步到暂存区中的变更撤销了。
此时,再次比较工作区和暂存区的差异,如下:
$ git diff
diff --git a/f1 b/f1
index d9e310a..2041f47 100644
--- a/f1
+++ b/f1
@@ -1 +1,2 @@
test file1
+The second line in the f1 file
diff --git a/f2 b/f2
index d15d3b2..4d9f2f1 100644
--- a/f2
+++ b/f2
@@ -1 +1,2 @@
test file2
+The second line in the f2 file
可见,工作区中仍然是存在最新的变更内容的,只是暂存区中已经是"干净"的状态了(与当前分支最新提交的状态相同)。
上例中,我们一次性将所有暂存区中的修改都消除了,其实我们也可以指定只操作某个文件,操作如下:
我们先将工作区的变更再次同步到暂存区
$ git add -A
查看仓库状态,发现f1和f2的变更都已经同步到了暂存区。
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: f1
modified: f2
假设此时,我们只是想要从暂存区去除f2的变更,f1的变更仍然保留在暂存区中,那么我们可以执行如下命令:
$ git reset HEAD -- f2
Unstaged changes after reset:
M f2
执行上述命令后,再次查看仓库状态,可以看到如下信息。
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: f1
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: f2
从返回信息中可以看出,f1的变更状态仍然保存在暂存区,而f2的变更则未暂存。
从目前的状况来看,工作区、暂存区、以及最近的提交中的内容都是不同的,f1文件的变更已经存在于暂存区,而f2文件的只存在于工作区,在最近的提交中,则没有这两个文件的最新变更,因为我们还未根据任何最新的变更创建提交,如果此时我后悔了,我想要将所有区域全部恢复到目前最近一次提交中的状态,我该怎么办呢?也就是说,我想要放弃所有工作区和暂存区中的变更,无论是已经暂存的变更,还是未暂存的变更,我都不想要了,我现在就想让所有逻辑区域中的内容回到上一次提交时的状态,我该怎么办呢?我们可以使用如下命令:
$ git reset --hard HEAD
HEAD is now at 1a09207 init, add f1 and f2
执行上述命令,即可将所有区域还原到与最新的提交相同的状态,看到上述命令你可能会觉得特别熟悉,这条命令不就是我们前文中使用过的版本回退命令么?在前文中我们总结过,使用" git reset --hard"命令可以回退到之前的任意一个提交时的状态,只需要利用" git reset --hard"命令指定对应的commit ID即可,而前文中又总结过,"HEAD"表示当前分支的最新提交(此处可以把HEAD替换成最新提交的commit ID,效果是相同的),所以,当我们执行"git reset --hard HEAD"命令时,你可以理解成我们把所有逻辑区域都回退到了当前分支最新提交时的状态。
到目前为止,我后悔了两次,并且使用了如下两条命令:
git reset HEAD
git reset --hard HEAD
我们使用了"git reset HEAD"命令将所有已经暂存的变成从暂存区撤销了(即暂存区与最近提交中的状态一致)。
我们使用了"git reset --hard HEAD"命令将所有逻辑区域恢复成了最近的提交中的状态(即工作区、暂存区都与最近提交中的状态一致)。
你肯定已经发现了规律,其实,上述两条命令无非就是将最近的提交中的内容覆盖到了不同的逻辑区域中,换句话说就是:
"git reset HEAD"命令将最近提交中的内容覆盖到了暂存区
"git reset --hard HEAD"命令将最近提交中的内容覆盖到了暂存区和工作区
其实,当我们使用 "git reset HEAD"命令时,相当于使用了"git reset --mixed HEAD"命令,这两条命令是等效的,因为"git reset"命令的默认选项就是"--mixed",所以当我们不添加任何选项时,默认使用"--mixed"选项,所以,我们可以总结如下
"git reset --mixed HEAD"命令可以将已经暂存到暂存区中的变更撤销(或者说将最近提交中的内容同步到暂存区)
"git reset --hard HEAD"命令可以将最近提交以后的所有变更撤销,无论是否暂存(或者说将最近提交中的内容同步到工作区和暂存区)
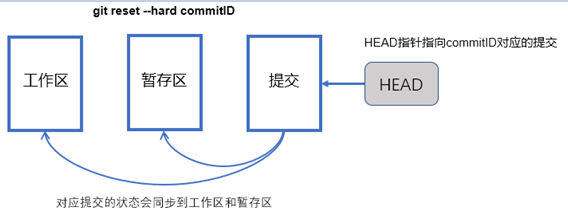
现在来扩展一下,上述命令其实不仅仅适用于最新的提交,我们还可以把上述命令中的"HEAD"替换成任意一个提交的哈希码(commit ID),比如如下命令:
"git reset --hard commitID"
"git reset --mixed commitID"
上述两条命令作用如下
"git reset --hard commitID"命令会将HEAD指针指向commitID对应的提交,并且将对应提交中的内容同步到工作区(就像前文中执行回退操作时那样,HEAD指针、暂存区,以及工作区全部回到了指定提交时的状态,由于HEAD指针的指向也发生了变化,所以当前分支的最新提交也会变成commitID对应的提交),如下图所示
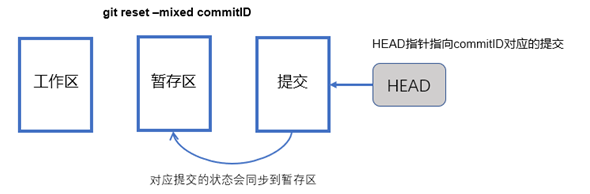
"git reset --mixed commitID"命令会将HEAD指针指向commitID对应的提交,并且将对应提交中的内容同步到暂存区(HEAD指针以及暂存区中的内容都发生了变化,但是不会影响工作区,也就是说,当前分支的最新提交会变成commitID对应的提交,对应提交的状态会同步到暂存区,但是工作区中的内容或者变更不受影响),如下图所示:
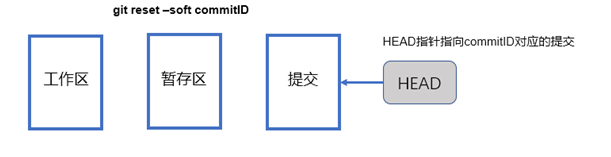
说到底,我们就是利用了"git reset"命令的不同选项,来操作了HEAD指针以及不同的逻辑区域罢了,除了"--mixed"选项和"--hard"选项,还有一个"--soft"选项,使用"--soft"选项时命令如下
"git reset --soft commitID"
此命令只将HEAD指针指向commitID对应的提交,但是不会操作暂存区和工作区,也就是说,当前分支中的最新提交会变成commitID对应的提交,工作区和暂存区中的内容或者变更不会受到任何影响,如下图所示:
我们可以用一张表格来总结git reset命令的不同选项影响的区域,如下表所示:
| 工作区 | 索引 | HEAD | |
|---|---|---|---|
| --soft | 否 | 否 | 是 |
| --mixed | 否 | 是 | 是 |
| --hard | 是 | 是 | 是 |
需要注意的是,在一个人使用git进行版本管理时,你可以任性的使用git reset命令,但是当多人协作使用git仓库管理代码时,使用git reset命令需要当心,因为,当多人协作使用git时,别人可以通过远程仓库获取到你已经发布的提交(我们可以将提交推送到远程仓库中,以便其他同事获取到我们修改的最新的代码,远程仓库我们还没有总结,此处先不用纠结,我们只要知道远程仓库可以帮助我们方便的发布提交,以便共享给他人使用即可),如果我们通过git reset命令回退了已经发布的提交,并且将回退后的状态推送到了远程仓库,则会影响到其他人使用git,由于我们还没有总结远程仓库的相关内容,所以不理解没关系,先记住就好,到总结远程仓库的知识点时,我们自然会理解的。
通过上述总结,我们已经知道了如何将暂存区的变更撤销,以及如何将工作区和暂存区的变更全部撤销,除了这些情况下的撤销,你可能还会遇到一些别的情况,比如,你只想撤销工作区的变更,该怎么办呢?细分之下,这里有两种情况:
情况一:你只是在工作区进行了变更,还没有将对应变更添加到暂存区,此时你后悔了,你想要将工作区中的修改撤销,让工作区还原成最近一次提交时的样子。
情况二:你已经将部分变更添加到了暂存区,然后你又接着干活,在工作区产生了新的变更,这些新的变更还没有添加到暂存区,此时你后悔了,你想要将工作区中的新的变更(还没有添加到暂存区的新的变更)撤销,让工作区还原成最近一次暂存时的样子。
无论是情况一,还是情况二,我们都能通过同一条命令来撤销工作区中的修改,不过我们还是分情况来说。
我们先说说情况一
仍然使用刚才的测试仓库进行测试,两个测试文件,f1和f2,文件内容如下:
$ ls
f1 f2
$ cat *
test file1
test file2
这些内容已经存在于第一个提交当中
$ git log --oneline
1a09207 (HEAD -> master) init, add f1 and f2
现在,我分别对两个文件做一些修改,修改如下:
$ echo 111 >> f1
$ echo 222 >> f2
我分别在两个文件中添加了新行,但是我并没有将文件的变更添加到暂存区,git仓库状态如下
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: f1
modified: f2
no changes added to commit (use "git add" and/or "git commit -a")
假设此时我后悔了,我想要将f2文件恢复成当前分支中最新的提交中f2文件的状态,则可以使用如下命令
$ git checkout -- f2
执行上述命令后,你会发现f2中的变更已经撤销了
如果你想要的一次性将所有工作区的变更全部撤销,也可以仓库的根目录中执行如下命令
$ git checkout -- ./*
执行上述命令可以将所有工作区的变更全部撤销,注意,这里指的工作区的所有变更是指已经被git跟踪的文件的变更,如果是新创建的文件,还没有被加入到版本库,则不能使用"git checkout -- ./*"命令撤销。
情况一说完了,现在来聊聊情况二
我又将f1和f2恢复到了最初的状态
$ ls
f1 f2
$ cat f1
test file1
$ cat f2
test file2
此时,我先对f1文件进行一次修改,然后将这次的变更添加到暂存区,操作如下:
$ echo 111 >> f1
$ git add f1
将这次修改添加到暂存区以后,我继续修改f1,操作如下
$ echo 111111111111 >> f1
$ cat f1
test file1
111
111111111111
我又在f1文件这种添加了一行新行。
假设此时,我后悔了,我想要将f1文件恢复到刚刚添加到暂存区时的状态,该怎么办呢?简单,仍然是使用git checkout命令即可,命令如下:
$ git checkout -- f1
$ cat f1
test file1
111
可以看到,执行"git checkout -- f1"命令后,工作区中最新的变更撤销了,变成了最近一次暂存时的状态。
从上述示例可以总结出一个规律,就是通过"git checkout -- file"命令可以帮助我们撤销工作区中的变更,但是这种撤销是分情况的,如果你撤销的文件已经添加到了暂存区中,并且在那之后又在工作区中进行了新修改,那么"git checkout -- file"命令会将工作区中的最新的变更撤销,将文件的状态还原成上次暂存时的状态,如果暂存区中并没有对应的文件的变更,那么"git checkout -- file"命令会将工作区中的变更撤销,将文件的状态还原成上次提交时的状态。
小结:
将上述命令进行总结,以便回顾
首先要注意,如果提交已经推送到远程仓库,操作这些提交时需谨慎。
撤销已经添加到暂存区中的修改,即让暂存区与最近的提交保持一致,可以使用如下命令,如下三条命令等效
git reset
git reset HEAD
git reset --mixed HEAD
也可以针对某些文件撤销暂存区中的修改,命令如下
git reset HEAD -- file1 file2
撤销所有暂存区和工作区中的所有变更
git reset --hard HEAD
回退到指定的提交
git reset --hard commitID
你已经将部分提交暂存到了暂存区,然后继续在工作区工作,工作区产生了新的变更,但是这些新变更没有添加到暂存区,此时你创建了提交,刚刚创建完提交你就后悔了,你想要的回到提交创建前一刻的状态,可以使用如下命令
git reset --soft HEAD~
使用如下命令可以撤销工作区中file1文件的相关变更,可以细分为两种情况
git checkout -- file1
情况一:你先修改了file1,并且暂存了,然后又修改了file1,在工作区产生了新的变更,此时执行上述命令,会将工作区中最新的变更撤销,工作区中的file1将会变成暂存区中file1的状态。
情况二:你修改了file1,暂存区中没有file1相关的变更,此时执行上述命令,会将工作区中最新的变更撤销,工作区中的file1将会变成最近一次提交中file1的状态。
Git之旅(11):合并分支详解
我们知道,不同分支中的提交是互不影响的,在实际的工作中,不同的分支通常对应了不同的功能和场景,或者对应着不同的开发人员,又或者对应着不同的代码模块,总之,我们可以利用分支,将"提交"从某个逻辑角度隔离开,让它们之间互不影响,以便在不影响他人或者其他逻辑的情况下完成工作,不过,当某个分支中的工作完成后,我们通常需要将这条分支与其他分支进行合并,以便多个分支的代码能够汇聚到一起,从而获取到一份更加全面、更加完整的可用代码,所以,合并分支也是我们必须掌握的技能,这篇文章我们就来总结一下怎样合并分支。
合并分支的操作其实不难,只是想要说明白,需要费一些口舌,因为在执行"合并"操作时,我们可以根据具体情况,选择不同的合并模式去合并,不同的合并模式对应了不同的命令参数,而且在合并的过程中,还可能遇到"冲突",听到这里是不是觉得有些麻烦,不用害怕,其实理解了原理以后是非常简单的,为了说明白原理,我们先来看一些示意图,理解了示意图以后,再去结合实际命令,搞定合并分支的操作简直不要太简单,也请阅读这篇文章的朋友一口气将此文读完,阅读中如果遇到问题,先记下来,等读完了这篇文章,再去回顾这些问题。
为了更好的理解,我们从头开始聊,先聊聊合并分支之前会发生的事情,示意图如下
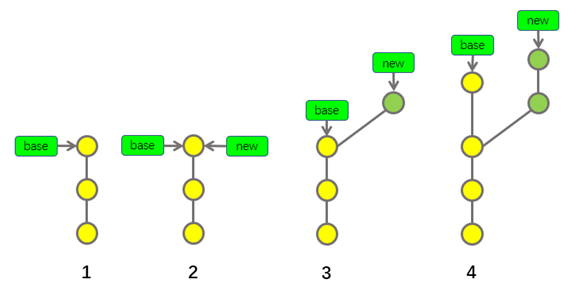
此示意图并没有涉及到任何合并操作,而是描述了合并分支之前,两个分支的创建过程。
上图中的第1步表示已经存在的一条分支,这条分支的名字是base。
第2步表示基于base分支,创建了new分支,此时,base分支的指针和new分支的指针都指向了最新的提交。
第3步表示我们在new分支中创建了新的提交。
第4步表示base分支也产生了新的提交,new分支也产生了新的提交,两个分支的指针分别指向了自己分支的最新提交,换句话说就是,从分叉点开始以后,两个分支各自产生了属于自己的提交。
有了前文作为基础,看明白上图肯定不在话下,我们接着聊。
上图中有两个分支,base分支和new分支,如果,我们想要将两个分支合并,该怎么做呢?没错,我们只需要将一条分支合并到另外一条分支上就行了(听上去似乎是句废话),但是,仔细想想,此处有一个小问题,我是把new分支合并到base分支上呢?还是将base分支合并到new分支上呢?有的朋友可能会问,有什么区别吗?听上去似乎是没有任何区别的呀。其实,还是有一些区别的,这里牵扯到一个合并方向的问题,让我们带着这个疑问,看看如下示意图
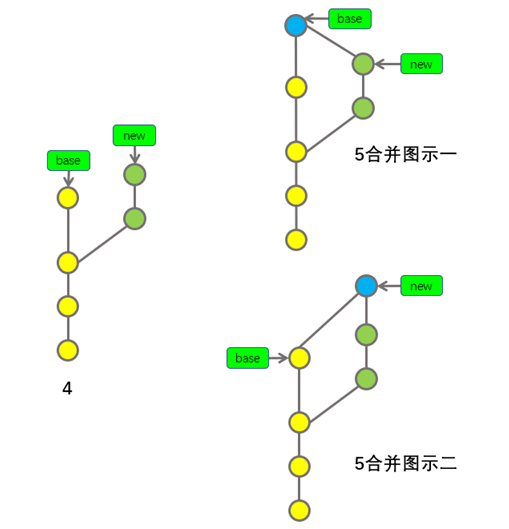
上图左侧的第4步我们已经解释过,第4步表示两个分支合并之前的状态,上图右侧有上下两个图示,分别表示两种合并方向,图示一表示将new分支合并到base分支上以后的状态,图示二表示将base分支合并到new分支上以后的状态。现在,我们分别解释一下上图中的两个图示。
我们先聊聊图示一(对比着第4步去看图示一更容易理解,第4步表示合并前,图示一表示合并后),图示一表示将new分支合并到base分支上,合并操作完成后(后文会细说具体操作,此处不用纠结),会产生一个新的提交(蓝色提交),这个新提交就是合并后的提交,它包含了两个分支中的最新代码,并且将它们合并到了一起,这个提交就是我们想要的合并后的状态,base分支的指针会指向这个新的蓝色提交,而new分支的指针则没有移动位置,仍然指向了new分支的最新提交(绿色提交)。为什么base分支的指针会指向最新的蓝色提交,而new分支的指针却保持原位呢?我们可以这样理解,在合并之前,base分支和new分支都有属于自己独有的提交(最新的黄色提交只属于base分支,绿色提交只属于new分支),如果我们是把new分支合并到base分支上,就表示要把只属于new分支上的变更合并到base分支上,对于base分支来说,会有新的变更进入(原来只属于new分支的变更对于base分支来说就是新变更),新变更进入后,base分支的内容会产生变化,所以,base分支需要一个新的提交(蓝色提交)来对应变化后的状态,于是,base分支的指针会指向最新产生的合并提交(蓝色提交),而对于new分支来说,并没有任何内容发生变动,所以new分支的指针仍然保持原位。
理解了图示一,再去理解图示二就非常简单了,道理其实是一样的,我们仍然对比着第4步去看图示二,图示二表示将base分支合并到new分支上,合并后会产生一个新的合并提交(蓝色提交),这个蓝色提交对应了合并后的状态,这个新的蓝色提交属于new分支,而不属于base分支,因为我们是把base分支合并到new分支上,这表示只属于base分支的变更会加入到new分支中,对于new分支来说,内容会发生变化,new分支需要一个新的提交来对应变化后的状态,而这个新的提交正是合并后产生的蓝色提交,于是,new分支将指针指向了蓝色提交,base分支的指针仍然保持原位。
你肯定已经总结出了规律,规律就是,在上述情况下,合并后的新提交属于合并到的目标分支。
除了上述情况,还有一种更加简单的合并场景,为了方便描述,还是先看示意图
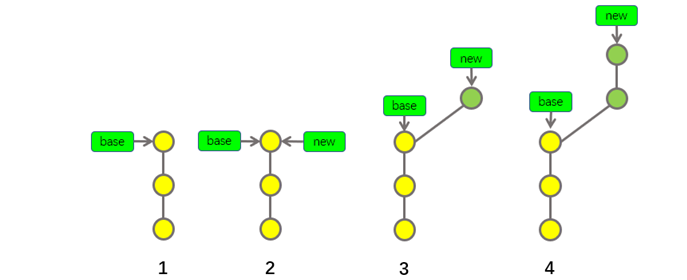
上例示意图中的前3步与之前描述的场景是一样的。
前3步表示:有一条base分支,基于base分支创建了new分支,在new分支上创建了新提交。
只是,上图中的第4步与之前描述的场景略微有些不同。
第4步表示:基于base分支创建new分支以后,只有new分支中产生了两个新提交,而base分支中还没有产生任何新提交。
如果在这种情况下,我想要将new分支合并到base分支,那么合并后会是什么样子呢?如果我们仍然按照之前介绍的思路去思考,合并后应该如下图中第5步所示:
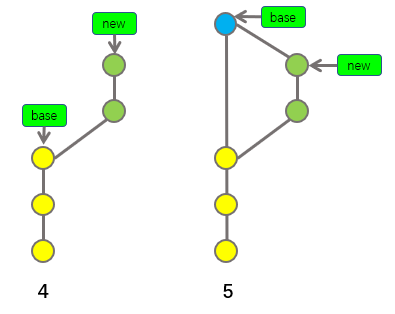
上图中第4步代表合并前的样子,第5步代表合并后的样子,因为new分支中有两个专属于new分支的提交,所以当我们把new分支合并到base分支时,base分支应该使用一个新提交来保存新进入的变更,所谓的新提交就是上图中的蓝色提交,上述示意图是完全没有任何问题的,只不过,在上图中第4步的情况下,我们还可以选择另外一种更加快捷的方式完成合并,这种快捷的合并方式被称之为"Fast-forward"(可译为"快进"或者"快速重定向"),我们一起来看看,使用"Fast-forward"的方式处理上述情况,会合并成什么样子,示意图如下:
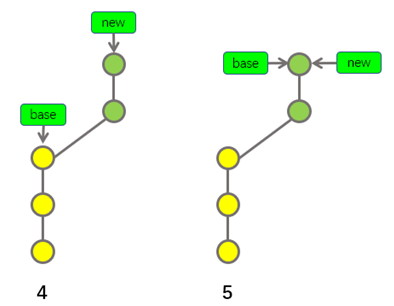
上图中第4步代表合并前的样子,第5步代表使用"Fast-forward"的方式合并后的样子,你肯定已经看明白了,由于基于base分支创建new分支以后,base分支中并没有产生任何新的提交,如果此时想要将new分支合并到base分支,只需要将base分支的指针指向到new分支的最新提交,即可让base分支包含new分支中的所有新变更。
这样说可能不容易理解,我们换个方式再解释一遍,new基于base创建,new新产生的所有变更都包含在上图中的绿色提交中,将new合并到base,就表示将new中的变更(所有绿色提交中包含的变更)也加入到base中,让绿色提交属于base分支最快的方法就是直接将base分支的指针直接指向最新的绿色提交。
上述直接移动指针进行合并的方式就是就是所谓的"Fast-forward","Fast-forward"的合并方式不会在base分支中产生任何合并提交(即不会产生示意图中的蓝色提交),而是利用了指针的移动,快速的实现了将new分支合并到base分支中的目的。
需要注意的是,"Fast-forward"的合并方式必须在满足条件的情况下才能使用,那么,什么情况下才能使用"Fast-forward"的合并方式呢?示意图如下:
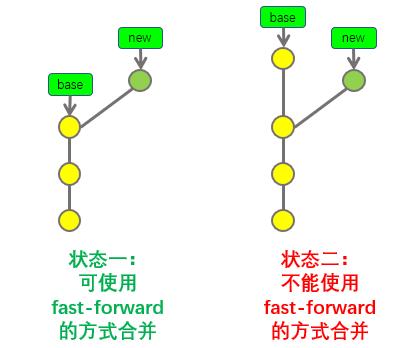
上图表示了在合并分支之前的两种状态,如果合并分支之前,base分支和new分支都有了属于自己分支的独有提交,就不能使用fast-forward的方式进行合并,如上图状态二所示,分叉点以后各分支都产生了属于自己的提交,这种情况下,就不能使用fast-forward,只能使用创建合并提交的方式进行合并。
当合并分支前的状态如状态一所示时,才能使用fast-forward的方式将new分支合并到base分支中,当然,在状态一的情况下,我们也可以选择使用创建合并提交的方式进行合并,后文会进行详细的演示,此处先行略过。
有的朋友可能会问,为什么上图中状态二的情况下就不能使用fast-forward模式呢?
其实仔细想想,就能想明白了,合并分支的最终目的是将两条分支中的内容完整的合并在一起,如果在状态二的情况下使用fast-forward模式直接移动分支指针,能够保证合并后的状态包含两个分支的所有内容吗?你可以在脑海中模拟一遍,如果移动base指针到绿色提交,就会丢失最新的黄色提交,如果移动new指针到最新的黄色提交,就会丢失绿色提交,这就是为什么在状态二的情况下不能使用fast-forward的原因,因为在这种情况下,fast-forward无法满足合并的最基本需求。
好了,概念说的差不多了,该动动手了。
为了能够更加方便的进行演示,我们来创建一个测试仓库,在测试仓库的master分支中创建一些基础的可以用于测试的提交,操作如下
$ git init test_repo
Initialized empty Git repository in D:/workspace/git/test_repo/.git/
$ cd test_repo/
$ echo "test1" > m1
$ echo "test11" > m11
$ git add -A
$ git commit -m "Initializes files of module 1"
[master (root-commit) 0da419c] Initializes files of module 1
2 files changed, 2 insertions(+)
create mode 100644 m1
create mode 100644 m11
$ echo "test2" > m2
$ echo "test22" > m22
$ git add -A
$ git commit -m "Initializes files of module 2"
[master 5b8c4c8] Initializes files of module 2
2 files changed, 2 insertions(+)
create mode 100644 m2
create mode 100644 m22
如上述操作所示,我创建了一个测试仓库,创建了一些测试文件,用这些文件创建了两个用于基础测试的提交。此处假设,测试仓库中的这些测试文件就是我的程序代码,假设我的程序由两个模块组成,模块一和模块二,m1文件和m11文件属于模块一,m2文件和m22文件属于模块二,我会为模块一和模块二分别创建两个分支,以便针对两个模块的修改互不影响,当我需要一份完整的代码时,会将模块一和模块二对应的分支合并到master分支中,以便从master分支获取到相对完整的代码,现在,我们需要分别为两个模块创建分支,b1分支和b2分支,操作如下:
$ git status
On branch master
nothing to commit, working tree clean
$ git branch b1
$ git branch b2
如上述操作所示,我基于master分支,创建了b1分支和b2分支,使用"gitk --all"命令,查看图形化界面,如下:

目前来说,这三条分支是完全相同的。
现在,我切换到b1分支,修改一些文件,模拟针对模块一代码的修改工作,并且在b1分支上创建提交,操作如下:
$ git checkout b1
Switched to branch 'b1'
$ cat m1
test1
$ echo "test m1" >> m1
$ cat m1
test1
test m1
$ git add m1
$ git commit -m "modify m1"
[b1 be27bc9] modify m1
1 file changed, 1 insertion(+)
同样,切换到b2分支,进行一些修改,模拟针对模块二的修改。操作如下
$ git checkout b2
$ cat m2
test2
$ cat m22
test22
$ echo "test m2" >> m2
$ echo "test m22" >> m22
$ cat m2
test2
test m2
$ cat m22
test22
test m22
$ git add -A
$ git commit -m "modify module2"
[b2 a73e5ca] modify module2
2 files changed, 2 insertions(+)
完成上述操作后,再次使用"gitk --all"命令,查看图形化界面,如下:

如上图所示,b1分支和b2分支分别产生了属于自己的独有提交,也就是说,通过上述操作,这两个提交中分别存放了两个模块的最新代码,master分支中不包含这两个模块中任何一个模块的最新代码,如果我想要将两个模块的最新代码汇聚到master分支中,只需要将b1分支和b2分支合并到master分支中即可,那么具体该怎么操作呢?
如果你想要的将A分支合并到B分支,就需要先检出到B分支,然后再执行合并命令将A分支合并进来,也就是说,需要先检出到目标分支,再执行合并命令。
先以合并b1分支为例,看看怎样将b1分支合并到master分支,具体操作如下:
#如果我们想要将某个分支的代码合并到master分支,需要先切换到master分支
$ git checkout master
Switched to branch 'master'
#查看一下m1文件的内容,并不是模块一最新的文件内容,m1的最新版本目前只存在于在b1分支中
$ cat m1
test1
#使用如下命令即可将b1分支合并到当前分支(当前分支是master分支),git merge命令就是用于合并分支的命令,此命令会将指定的分支合并到当前分支。
$ git merge b1
Updating 5b8c4c8..be27bc9
Fast-forward
m1 | 1 +
1 file changed, 1 insertion(+)
从上述命令的返回信息可以看出,当我们把b1分支合并到master分支时,git默认使用了"Fast-forward"模式,这是因为git发现,b1分支是基于master分支创建的,并且master分支并没有产生属于自己的独有的提交,所以,当我们需要把b1分支合并到master分支时,只需要将master的指针指向b1分支的最新提交即可,执行上述命令后,使用"gitk --all"查看图形化界面,如下:

正如我们所想,master分支的指针指向了b1分支的最新提交,也就是说,此时b1分支已经合并到了master分支中。
再次查看master分支中的m1文件内容,发现m1的内容已经变成了最新的版本
$ cat m1
test1
test m1
如上述操作所示,我们把b1分支合并到了master分支中,master分支中已经包含了模块一的最新版本的代码,但是目前,master分支中还不包含模块二的最新代码,查看master分支中模块二的文件,内容仍然是最初的,如下:
$ cat m2
test2
$ cat m22
test22
我们可以使用同样的方法即可将b2分支合并到master分支中。既然是想将b2分支合并到master分支中,就需要先检出到master分支,但是由于我们当前就处于master分支,所以就不用执行checkout命令了,直接执行merge命令即可,不过,在执行merge命令之前,请先思考一个问题,在当前状态下,如果将b2分支合并到master分支,还能使用"Fast-forward"模式吗?
答案是:不能。
为什么不能呢?为了更加容易理解,我们可以对比着图形化界面中的状态和之前的示意图中的状态去理解,如下:
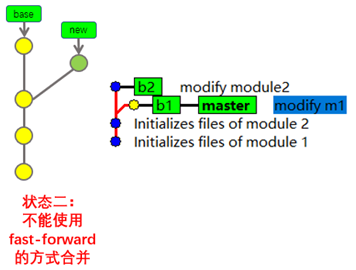
看到此处,聪明如你肯定已经完全明白了,master分支就相当于图示中的base分支,b2分支就相当于图示中的new分支,所以,在这种状态下,如果我们想要将b2分支合并到master分支中,则不能使用"Fast-forward"的模式进行合并,只能使用创建新提交的方法进行合并,换句话说就是,当我们将b2分支合并到master分支以后,会产生一个新的合并提交,注意,我们必须为这个新提交填写注释信息,否则将无法完成合并操作。
好了,理解了原理以后,我们开始动手合并吧。
执行如下命令将b2分支合并到当前分支(master分支):
$ git merge b2
注意,执行上述命令后,git会自动调用vim编辑器,并且自动生成如下图中的注释信息,下图中的注释信息都是为了"新提交"而准备的,刚才说过,我们必须为新提交填写注释信息,而下图中的注释信息则是git自动默认生成的,"Merge branch b2"表示这个新提交就是为了合并b2分支而产生的提交,你也可以根据自己的需要,修改如下注释信息,但是此处为了方便,直接使用默认的注释信息。

在vim编辑器的命令模式下输入wq,保存退出,即可使用默认的注释信息,退出vim后,看到如下返回信息
$ git merge b2
Merge made by the 'recursive' strategy.
m2 | 1 +
m22 | 1 +
2 files changed, 2 insertions(+)
此时,再次查看图形化界面,如下:

从上图可以看出,当我们将b2分支合并到master分支以后,产生了一个新的提交,这个提交属于master分支,这个提交中包含了来自b2分支中的变更,这个提交的注释信息是"Merge branch b2",正是刚才git默认生成的注释信息。
其实,我们每次执行git merge命令时,git都会先去尝试能不能使用"Fast-forward"的模式进行合并,如果能,就默认使用"Fast-forward"的模式进行合并,如果不能,就创建一个合并提交进行合并。
好了,说了这么多,其实都是非常简单的理论和命令,多看两遍,多做两边,就能很快的理解了。
现在,我们着重的看一下merge命令以及常用的一些参数。
git merge A
上述命令表示将A分支合并到当前分支。
git merge --no-ff A
上述命令表示将A分支合并到当前分支,但是明确指定不使用"Fast-forward"的模式进行合并, "--no-ff"中的"ff"表示 "Fast-forward",即使合并条件满足"Fast-forward"模式,也不使用快进的方式进行合并,而是使用创建合并提交的方式进行合并。
git merge --ff-only A
上述命令表示将A分支合并到当前分支,但是只有在符合"Fast-forward"模式的前提下才能合并成功,在不符合"Fast-forward"模式的前提下,合并操作会自动终止,换句话说就是,当能使用"Fast-forward"模式合并时,合并正常执行,当不能使用"Fast-forward"模式合并时,则不进行合并。
git merge --no-edit A
上述命令表示将A分支合并到当前分支,但是没有编辑默认注释的机会,也就是说,在创建合并提交之前不会调用编辑器(上文的示例中会默认调用vim编辑器,以便使用者能够有机会编辑默认的注释信息),换句话说就是,让合并提交直接使用默认生成的注释,默认注释为" Merge branch 'BranchName' "
git merge A --no-ff -m "merge A into master,test merge message"
上述命令表示将A分支合并到当前分支,并且使用-m参数指定合并提交对应的注释信息。
注意,为了保险起见,需要同时使用"--no-ff"参数,否则在满足"Fast-forward"模式的情况下,会直接使用"Fast-forward"模式进行合并,从而忽略了-m选项对应的注释信息(因为使用"Fast-forward"模式合并后不会产生新提交,所以为提交准备的注释信息会被忽略)
Git之旅(12):解决冲突
如果两个分支中的同一个文件中的同一行的内容不一样,当我们合并这两个分支时,就会出现冲突,因为git无法判断我们想要以哪个内容为准,所以需要我们人为介入去确认,人为介入确认内容的过程,就是解决冲突的过程。
为了方便演示,我们先来创建一个测试仓库,并且创建两个分支出来,然后分别修改这两个分支中的同一个文件中的同一行,以便之后合并时能够出现冲突,过程如下:
$ git init testgit
Initialized empty Git repository in D:/workspace/git/testgit/.git/
/d/workspace/git
$ cd testgit/
/d/workspace/git/testgit (master)
$ echo 1 > testfile
/d/workspace/git/testgit (master)
$ git add testfile
/d/workspace/git/testgit (master)
$ git commit -m "add test file"
[master (root-commit) d808b6e] add test file
1 file changed, 1 insertion(+)
create mode 100644 testfile
/d/workspace/git/testgit (master)
$ echo 2 >> testfile
/d/workspace/git/testgit (master)
$ git add testfile
/d/workspace/git/testgit (master)
$ git commit -m "add 2"
[master 6b5149f] add 2
1 file changed, 1 insertion(+)
/d/workspace/git/testgit (master)
$ cat testfile
1
2
/d/workspace/git/testgit (master)
$ git checkout -b new
Switched to a new branch 'new'
/d/workspace/git/testgit (new)
$ cat testfile
1
2
通过上述步骤,我们创建了一个测试文件testfile,在testfile里面写了两行内容,并且创建了两个初始提交,然后,我们基于master分支创建了new分支,现在,new分支和master分支是完全相同的,我准备在两个分支中分别修改testfile的第二行,让new分支和master分支中的testfile的第二行的内容变的不同。
先来操作new分支,操作如下:
/d/workspace/git/testgit (new)
$ cat testfile
1
2
/d/workspace/git/testgit (new)
$ vim testfile
/d/workspace/git/testgit (new)
$ cat testfile
1
2new
/d/workspace/git/testgit (new)
$ git add testfile
/d/workspace/git/testgit (new)
$ git commit -m "2 new"
[new 7d188a4] 2 new
1 file changed, 1 insertion(+), 1 deletion(-)
如上所示,我将new分支中的testfile文件中的第二行从"2"改成了"2new",并且基于这个修改,在new分支中创建了新提交。
new分支操作完了,现在来操作master分支。
/d/workspace/git/testgit (new)
$ git checkout master
Switched to branch 'master'
/d/workspace/git/testgit (master)
$ cat testfile
1
2
/d/workspace/git/testgit (master)
$ vim testfile
/d/workspace/git/testgit (master)
$ cat testfile
1
2master
/d/workspace/git/testgit (master)
$ git add testfile
/d/workspace/git/testgit (master)
$ git commit -m "2 master"
[master 3c5ea03] 2 master
1 file changed, 1 insertion(+), 1 deletion(-)
如上所示,我将master分支中的testfile文件中的第二行从"2"改成了"2master",并且基于这个修改,在master分支中创建了新提交。
现在,在master分支和new分中,都有了属于了自己的提交,如下图所示,而且,这些提交都是针对testfile文件的第二行所做的修改。

假设,此时我们想要合并两个分支,就会出现所谓的冲突,我们来试试。
当前我们处于master分支中,现在尝试直接把new分支合并到当前分支,命令如下:
git merge new
当我们执行上述命令后,会看到如下返回信息
Auto-merging testfile
CONFLICT (content): Merge conflict in testfile
Automatic merge failed; fix conflicts and then commit the result.
/d/workspace/git/testgit (master|MERGING)
$
那么上述返回信息是什么意思呢?大概意思就是,合并时出现冲突啦,冲突在testfile中,自动合并失败啦,快来人解决冲突啊。
而且,我们能够发现,在git bash中,如果合并时遇到冲突,在git bash所显示的路径中就会添加上如下字样
"(分支名|MERGING)"
就像上例中的 "/d/workspace/git/testgit (master|MERGING)" 一样, "(分支名|MERGING)"表示当前分支还处于"合并中"的状态,也就是说,合并操作并没有完成,还在进行中。
此时,如果我们执行git status命令,能够看到如下信息
/d/workspace/git/testgit (master|MERGING)
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: testfile
no changes added to commit (use "git add" and/or "git commit -a")
从上述信息可以看出,我们当前处于master分支,存在没有合并完成的路径(存在没有合并完成的文件)。
而且git提示我们,现在我们有两种选择,这两种选择分别如下:
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
第一种选择是:修复冲突,然后将确定后的内容创建提交。
第二种选择是:使用"git merge --abort"命令放弃合并。
看来git还是很人性化的,在合并时如果遇到冲突,我们可以选择放弃合并,就像从来都没有发生过任何事情一样,也可以选择解决冲突,完成合并,后文会演示这两种操作,此处不用纠结。
从返回信息的"Unmerged paths"中,我们能够找到所有未完成合并的文件(存在冲突的文件),而上例中,合并时出现冲突的文件就是testfile文件,那么,我们来看看,在产生冲突以后,testfile文件变成了什么样子。
/d/workspace/git/testgit (master|MERGING)
$ cat testfile
1
<<<<<<< HEAD
2master
=======
2new
>>>>>>> new
如上所示,当冲突发生以后,git会自动将冲突的部分标注出来。
git会使用如下结构,将冲突的内容标注起来
<<<<<<< HEAD
=======
>>>>>>> BranchName
git会将当前分支中的内容放在 "<<<<<<< HEAD" 与 "=======" 之间。
git会将new分支中的内容放在 "=======" 与 "<<<<<<< new" 之间。
也就是说,git并不能确定,是使用"2master"作为最终的内容,还是使用"2new"作为最终的内容,所以,需要我们人为的进行裁决,决定最终的内容。
到目前为止,我们已经在合并时遇到了冲突,并且查看了冲突所在的testfile文件,我们可以选择放弃合并,也可以选择解决冲突,我们先来演示一下,怎样放弃合并,正如提示信息中所示,我们只要执行"git merge --abort"命令即可放弃合并,我们来试试,操作如下:
/d/workspace/git/testgit (master|MERGING)
$ git merge --abort
/d/workspace/git/testgit (master)
$ git status
On branch master
nothing to commit, working tree clean
/d/workspace/git/testgit (master)
$ cat testfile
1
2master
如上例所示,当我们执行git merge --abort命令以后,git就取消了本次合并操作,此时,再次执行"git status"命令,可以看到master分支中没有任何需要修改和提交的内容,查看testfile的内容,会发现testfile中的内容与执行合并操作之前相同,就好像没有执行过任何合并操作一样。这就是在冲突时放弃合并的方法,很容易吧。
我们已经掌握了怎样在合并产生冲突时放弃合并,现在我们来看看怎样在发生冲突的情况下完成合并。
再次执行如下合并命令,以便合并时产生冲突。
/d/workspace/git/testgit (master)
$ git merge new
Auto-merging testfile
CONFLICT (content): Merge conflict in testfile
Automatic merge failed; fix conflicts and then commit the result.
如你所见,自动合并失败了,因为有冲突在testfile文件中,git提示我们,可以修复冲突,然后将修复后的结果提交。
查看testfile文件的内容,发现冲突的部分已经被git标注好了,如下:
/d/workspace/git/testgit (master|MERGING)
$ cat testfile
1
<<<<<<< HEAD
2master
=======
2new
>>>>>>> new
我们可以按照自己的需求,修改冲突的部分,此处假设,我想要使用"2 master 2 new"作为最终的内容,我只需要通过编辑器,将冲突标注的部分改为"2 master 2 new"即可,操作如下(使用vim编辑器编辑文本):
/d/workspace/git/testgit (master|MERGING)
$ vim testfile
/d/workspace/git/testgit (master|MERGING)
$ cat testfile
1
2master 2new
编辑后的testfile内容如上所示
好了,冲突的部分已经被人为干预解决了,不过,这并不代表整个合并操作完成了,在解决所有冲突文件以后,我们还需要将最终的状态创建为提交,才算完成了整个合并操作,整个流程操作如下:
/d/workspace/git/testgit (master|MERGING)
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: testfile
no changes added to commit (use "git add" and/or "git commit -a")
/d/workspace/git/testgit (master|MERGING)
$ git add testfile
/d/workspace/git/testgit (master|MERGING)
$ git status
On branch master
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: testfile
/d/workspace/git/testgit (master|MERGING)
$ git commit -m "merge new branch into master branch"
[master 67f725c] merge new branch into master branch
/d/workspace/git/testgit (master)
$
如上述操作所示,我们先执行了git status命令,如果你在git bash中也执行了git status命令,会看到返回信息中testfile是红色的,也就是说,testfile目前的状态还未添加到暂存区,于是,为了方便提交,我们执行了git add命令,将testfile添加到了暂存区,再次执行git status命令,可以看到testfile已经变为绿色,最后,我们使用git commit命令创建了提交,将解决冲突后的合并状态永久的保存了在了新提交中。
此时,使用gitk --all命令查看图形化界面,如下:

可以看到,合并完成了,在合并过程中虽然遇到了冲突,但是我们人为介入,解决了冲突,并且在最后创建了提交,将合并后的状态保存在了新的合并提交中。
细心如你肯定已经发现了,上图所表达的状态其实与前文中正常合并后的状态一样(前一篇文章中我们演示了在没有冲突的情况下顺利完成合并的操作,其合并后的状态与上图一样),只不过,当遇到冲突时,合并提交不会自动创建,而是会给我们解决冲突的机会,当我们将所有冲突解决以后,再手动的创建合并提交,也就是刚才演示的解决冲突、创建提交的过程。总结成一句话就是,在合并时,如果没有冲突,就自动创建合并提交,如果存在冲突,需解决冲突后手动创建提交。
其实,在没有冲突能够正常合并的情况下,我们也可以明确指定不自动创建提交,而是手动的创建提交,我们只需要借助"--no-commit"参数即可,示例如下
git merge --no-commit new
上述命令表示,将new分支合并到当前分支,在没有冲突的情况下,也不自动创建提交,而是给我们一个修改的机会,我们可以将内容进行进一步修改后,以最后敲定的结果创建提交。快来自己创建一个测试场景,试试上面的"--no-commit"参数吧,此处就不进行演示了。
当分支合并完成后,我们就可以将不需要的分支删除了,比如上例中的new分支,我们已经将new分支的内容合并到了master分支中,所以,如果不再需要在new分支上进行操作,即可删除new分支,示例命令如下:
/d/workspace/git/testgit (master)
$ git branch -d new
Deleted branch new (was 7d188a4).
/d/workspace/git/testgit (master)
$ git branch -a
* master
如上述操作所示,我们想要删除new分支,所以执行了"git branch -d new"命令,"-d"参数为删除之意,需要注意,你如果想要删除new分支,就不能处于new分支中,必须先切换到其他分支中,而上例中,我们删除new分支时,处于master分支中,所以可以正常删除new分支,删除分支后,使用"git branch -a"命令查看所有分支,已经看不到new分支了,可以确认,new分支已经被删除了。
此时,如果使用gitk --all命令查看图形化界面,会看到如下界面:

从上图中可以看出,new分支的分支标签已经被删除了,目前只有master分支
在有些情况下,我们使用"-d"参数,是无法删除对应分支的,比如,当git检测到,你要删除的分支还没有合并到其他分支中,git会出现类似如下提示:
error: The branch 'new' is not fully merged.
If you are sure you want to delete it, run 'git branch -D new'.
在new分支没有完全合并到其他分支中时,如果执行"git branch -d new"命令,就会出现上述提示,这是git为了保险起见而进行的提示,如果你无论如何就是想要删除new分支,无论它是否被完全合并都想要删除它,可以使用"-D"选项(大写D),即可强制删除对应的分支,示例如下:
git branch -D new
Git之旅(13):常见场景与技巧(一)
为了方便演示,我们先来创建一个测试仓库,命令如下:
/d/workspace/git
$ git init test_repo
Initialized empty Git repository in D:/workspace/git/test_repo/.git/
/d/workspace/git
$ cd test_repo/
/d/workspace/git/test_repo (master)
$ echo 11 > testfile1
/d/workspace/git/test_repo (master)
$ cat testfile1
11
/d/workspace/git/test_repo (master)
$ git add testfile1
/d/workspace/git/test_repo (master)
$ git commit -m "init commit, testfile1"
[master (root-commit) 2feec01] init commit, testfile1
1 file changed, 1 insertion(+)
create mode 100644 testfile1
/d/workspace/git/test_repo (master)
$ git log --oneline
2feec01 (HEAD -> master) init commit, testfile1
如上例所示,我们在测试仓库中创建了一个测试文件testfile1,然后创建了一个初始化的提交。
现在,我继续修改testfile1文件,命令如下:
/d/workspace/git/test_repo (master)
$ echo 12 >> testfile1
/d/workspace/git/test_repo (master)
$ cat testfile1
11
12
如上所示,我在testfile1中追加了一行新内容,如果我想要将新的修改创建为提交,那么应该先将这次的修改添加到暂存区,然后再创建提交,此时,如果你使用"git status"命令查看状态,会看到我们还没有将testfile1的最新修改添加到暂存区,如下所示
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: testfile1
no changes added to commit (use "git add" and/or "git commit -a")
正常来说,我们应该先执行"git add"命令,然后再执行"git commit"命令创建提交,其实,我们还有更加方便的方法,就是直接执行如下命令:
git commit -am "second commit"
上述命令的作用就是将暂存操作和提交操作一次性完成,其效果相当于我们先执行了"git add testfile1"命令,然后又执行了git commit -m "second commit"命令,我们来执行一下,看一下效果,如下:
/d/workspace/git/test_repo (master)
$ git commit -am "second commit"
[master ac238f9] second commit
1 file changed, 1 insertion(+)
/d/workspace/git/test_repo (master)
$ git log --oneline
ac238f9 (HEAD -> master) second commit
2feec01 init commit, testfile1
如上例所示,执行git commit -am "second commit"命令后,第二个提交就被创建了,省去了手动执行git add命令的步骤。
需要注意的是,如果你的工作区中存在完全新创建的文件(从未被git跟踪过,刚刚从工作区中新建出来),那么"git commit -am"命令并不会将新建的文件添加到暂存区。
当你觉得,目前工作区中的所有变更(被跟踪过的文件的变更)适合创建在同一个提交中时,使用"git commit -am"命令还是很方便的,这样可以省略一步git add的操作。
在前文中,我们一直在添加文件,修改文件,从来没有删除过文件,现在我们来测试一下删除文件的操作,就拿删除testfile1文件为例吧, 示例操作如下:
/d/workspace/git/test_repo (master)
$ rm testfile1
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: testfile1
no changes added to commit (use "git add" and/or "git commit -a")
如上例所示,我执行了删除命令,删除了testfile1文件,执行删除命令后,在文件系统中已经看不到testfile1文件了,此时执行"git status"命令,会发现git提示我们,有一个变更还没有暂存,也就是说,删除文件的操作,也会被git理解成一个变更,既然是变更,就要从工作区添加到暂存区以后,才能够创建在提交中,从"git status"命令的提示信息中可以看到,我们可以使用"git add"命令或者"git rm"命令将这个删除文件的变更添加到暂存区,那么我们一起来操作一下,如下所示:
/d/workspace/git/test_repo (master)
$ git add testfile1
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: testfile1
执行git add testfile1命令后,删除testfile1文件的变更就添加到了暂存区,之后,我们就能够直接进行提交了。
总结一下,上述删除testfile1文件的步骤一共执行了两步操作:
第一步:在文件系统中删除testfile1文件。
第二步:在git中将删除文件的变更添加到暂存区。
其实,上述两步操作可以通过一条命令来完成,这条命令就是刚才提到过的"git rm"命令
我们可以在没有从文件系统中删除testfile1的情况下,直接执行如下命令
git rm testfile1
执行完上述命令后,你会发现文件系统中的testfile1被删除了,而且使用"git status"命令查看,会发现变更已经自动添加到了暂存区,相当于一条命令完成了两步操作(同样需要注意,我们所说的被删除的文件,也是被git跟踪过的文件),此处就不进行示例了,快动手实验一下吧。
除了删除文件,我们可能经常会有对文件重命名的需求(对已经被git跟踪过的文件重命名),我们来模拟一遍,操作如下:
注:为了方便演示,我直接将刚才的testfile1还原回来,以便执行重命名的操作,还原的操作就不再赘述了,可以参考之前的文章:“后悔了,怎么办?”
/d/workspace/git/test_repo (master)
$ ls
testfile1
/d/workspace/git/test_repo (master)
$ mv testfile1 tf1
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: testfile1
Untracked files:
(use "git add <file>..." to include in what will be committed)
tf1
no changes added to commit (use "git add" and/or "git commit -a")
/d/workspace/git/test_repo (master)
$ git add -A
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: testfile1 -> tf1
如上述操作所示,我先使用mv命令在文件系统中重命名了testfile1,将testfile1重命名为tf1,之后,使用"git status"命令查看,发现git会把重命名的操作理解成先删除了testfile1,又创建了tf1,之后,我将变更添加到了暂存区,发现git自动将之前的变更识别为了重命名操作,那么,有没有更加方便的方法呢?必须有的,方法就是,不在文件系统中重命名testfile1,而是直接执行如下命令即可。
git mv testfile1 tf1
同样,为了方便演示,我将仓库还原成了没有重命名之前的状态,然后执行如下命令进行演示:
/d/workspace/git/test_repo (master)
$ ls
testfile1
/d/workspace/git/test_repo (master)
$ git mv testfile1 tf1
/d/workspace/git/test_repo (master)
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: testfile1 -> tf1
如上述命令所示,当我们使用"git mv"命令重命名文件后,重命名操作会自动添加到暂存区,从而省略了手动执行"git add"命令的步骤,还是很方便的。
小结
git commit -am "注释"
上述命令表示:省略"git add"操作,自动完成暂存并创建提交,换句话说就是,直接将工作区中的所有变更创建成一个提交,注意:完全新建没有被git跟踪过的文件不会自动暂存。
git rm testfile
上述命令表示:删除testfile文件,并自动将变更暂存,效果相当于在文件系统中删除testfile,然后手动暂存。
git mv testfile tf
上述命令表示:将testfile重命名成tf,并自动将变更暂存,效果相当于在文件系统中重命名了testfile,然以手动暂存。
Git之旅(14):远程仓库(一)
当多人需要通过git进行协作时,通常的做法是创建一个远程仓库,每个人把远程仓库克隆到本地,克隆后,每个人就在本地获取到了一个和远程仓库一样的git仓库,这样,每个人就可以在自己的本地库中对代码进行开发和管理,当你需要把自己本地产生的最新代码同步到远程仓库中时,就可以进行一个推送操作,将本地的最新代码推送到远程仓库中,同理,如果你想要从远程仓库中获取到别人推送的最新的代码,也可以进行一个拉取操作,将远程仓库的最新代码拉取到本地仓库中,换句话说就是,将远程仓库克隆到本地以后,大家通过本地仓库进行实际修改和版本管理,通过远程仓库进行代码的更新和交换,这样描述并不具象化,别着急,向下看。
看完上述描述,你可能会有如下疑问
1、如果之前有一个只有自己使用的本地仓库,现在突然想要多人协作,能否将已经存在于本地个人仓库中的内容同步到远程仓库中供大家使用呢?
2、如果多个人同时修改了自己本地仓库中的同一个文件,比如A文件,那么当他们都向远程仓库中推送A文件时,会出现冲突吗?同理,如果从远程仓库中拉取的最新代码与本地的代码存在冲突,该怎样解决呢?
3、一些其他的问题
咱们一个一个聊
首先咱们聊聊第一个问题,能否将现有仓库中的内容同步到新建的远程仓库中呢?答案是肯定的。
一开始,你可能是一个光杆司令,所有开发工作都是你一个人完成的,你并不需要与别人协作,所以你只是在你的电脑上创建了一个git仓库,然后通过这个本地的git仓库管理代码,经过一段时间的发展,你找到了一些志同道合的小伙伴,你们准备多人协作,共同开发,于是你们想要通过远程仓库协作工作,所以,你创建了一个远程仓库,但是新创建的远程仓库是一个空的仓库,里面什么也没有,大家想要基于你之前的工作成果继续开发,所以你们的首要目的是将你本地仓库中已有的内容同步到新创建的远程仓库中,以便远程仓库中存放的内容是最新的,然后其他人再通过克隆远程仓库的方式,在本地创建出一个本地仓库,这样所有人就都能够获取到一份相同的代码了,之后,所有人就能够通过自己的本地仓库进行工作了,如果需要更新或者交换代码,再依靠远程仓库进行。
如果是一个新的项目,完全可以直接先创建一个新的空的远程仓库,然后大家将远程仓库克隆下来,在本地仓库中丰富内容,然后将新内容推送到远程仓库中。
所以,是否存在已有的工作成果和git仓库,都不会影响你创建远程仓库,也不会影响你何时创建远程仓库,这样空口白话的描述可能还是有点难以理解,不如先来创建一个远程仓库,从头到尾的将整个过程测试一遍,结合实际去理解吧。
本文中会在github上创建远程仓库,github是一个代码托管平台,我们可以在github上免费的创建仓库,以便多人协作使用,除了GitHub,国际上比较著名的代码托管平台还有Bitbucket、GitLab,国内比较著名的代码托管平台有码云、coding等,你可以选择自己喜欢的代码托管平台创建远程仓库,本文中使用GitHub,早期的时候,在GitHub中创建的远程仓库分为公有仓库和私有仓库两种,公有仓库是所有人都能访问的远程仓库,通常开源项目代码的存放会选择使用公有仓库,私有仓库是只有指定的仓库成员才能够访问的远程仓库,早期的时候在github上创建私有仓库是收费的,后来可以免费的创建私有仓库了,但是之前我记得github上免费创建的私有仓库最多只能3个人进行协作,也就是说免费创建的私有仓库有人数限制,这么长时间过去了,不知道是否还是存在对应的限制,不过此处我们只是用于测试,即使有限制也不影响我们此处的测试,所以,我们会在github上创建一个远程仓库来进行演示。
首先,打开github官网,网址如下:
https://github.com
使用github账号登录,没有账户可以免费注册一个,如果你是新注册的账号,登录后可以看到如下图所示的 "创建仓库" 的按钮,点击此按钮
点击创建仓库按钮后,会让你填写远程仓库的基本信息,界面如下图
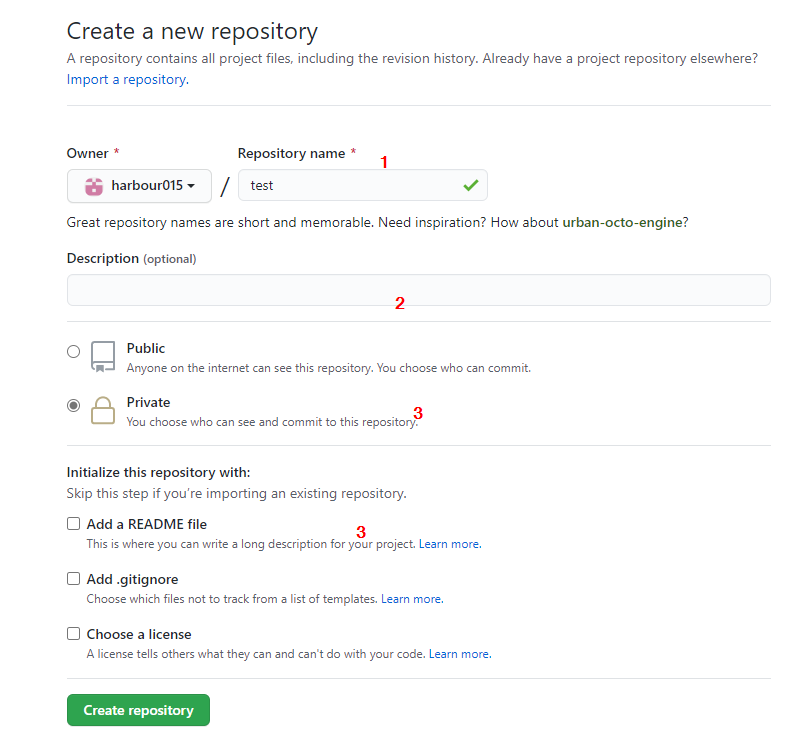
上图1的位置会让你填写仓库的名称,此处设置远程仓库的名称为test
上图2的位置可以填写远程仓库的相关注释
上图3的位置可以选择创建的远程仓库是公有仓库还是私有仓库,此处选择私有仓库
上图4的位置如果勾选,会在创建远程仓库时,自动在仓库中创建一个README文件,此处没有勾选
如上图所示,点击绿色的创建仓库按钮
点击创建仓库按钮后,可以看到如下图中的仓库地址提示,
通常情况下,代码托管平台会为我们提供两种格式的仓库地址,HTTPS格式的仓库地址,以及SSH格式的仓库地址
如果你点击上图中的HTTPS,就会看到对应的https格式的仓库地址,默认情况下会显示SSH格式的仓库地址,
由于我创建的是私有仓库,所以当你通过https地址克隆远程仓库时,会提示你输入github的用户名和密码,以便验证你是否有权限克隆当前的仓库,如果你创建了一个公有仓库,可以直接使用https地址克隆对应的仓库,不会要求你输入任何用户名和密码,如果是私有仓库,在执行克隆等操作时,都会提示你输入用户名密码进行身份验证,所以为了方便,我通常不会通过https地址操作私有的远程仓库,我通常习惯使用ssh地址克隆远程仓库,因为使用ssh地址只需要一次设置好相关的秘钥,之后就能很方便的操作所有有权限的远程仓库了,不需要重复的验证用户名和密码,如果你不明白我在说什么,没有关系,我们先照做,多做两边就熟悉了,除了上图中的远程仓库地址,你可能还会在页面中看到一些github推荐你执行的命令,这些命令对应了不同的使用场景,我们暂时先不用关心这些命令,等到我们了解了整个过程以后,再来看这些命令就一目了然了,所以,此处我们先不用在意它们,完成上述操作以后,其实远程仓库的创建操作就已经完成了,到目前为止,我已经在我的github账号下创建了一个名为test的远程仓库了,回到github的首页,你就会看到所有创建过的仓库列表,从仓库列表中已经可以看到我刚才创建的远程仓库test,如下图所示。
我们已经创建了一个新的空的远程仓库,但是我现在还没有把它克隆到本地,在将远程仓库克隆到本地之前,我们需要提前做一些配置,比如,配置ssh密钥,之前说过,我习惯使用远程仓库的ssh地址操作远程仓库,当我们通过这种地址操作远程仓库时,代码托管平台会通过ssh密钥验证你的身份,验证你是否有权限克隆当前的远程仓库,由于当前仓库是私有仓库,所以在使用ssh地址操作远程仓库时,需要同时满足如下两个条件,才能验证成功
条件一:你是仓库的成员之一,由于我创建了test仓库,所以我默认就是test仓库的管理员,也是成员,如果你想要参与到别人创建的项目中,则需要仓库管理员将你的github账号添加到仓库成员中,同理,你创建的仓库也可以将别人的github账号添加为成员。
条件二:你的github账户中有对应的公钥,这里所说的公钥是ssh密钥对中的公钥
由于我是在windows中安装的git,所以我们可以在git bash的命令行窗口中使用" ssh-keygen.exe"命令生成密钥对,如果你之前就有已经生成好的密钥对,也可以直接使用,假如你是新生成的密钥对,默认情况下,会在当前用户的家目录中的".ssh"目录中生成密钥对,也就是如下路径
C:\Users\用户名.ssh
当生成密钥对以后,我们需要做的就是将公钥配置到github账户中,以便github可以通过公钥验证我们的身份,私钥是我们自己保留的,不要泄露给任何人。
将公钥添加到github账号的具体步骤如下:
登录github账号后,点击右上角的账户图标,然后点击"Settings"菜单,如下图

进入页面后,点击左侧菜单中的"SSH and GPG keys"菜单,如下图
点击上述菜单后,可以看到绿色的 "New SSH Key" 按钮,点击绿色按钮进入添加ssh密钥的页面
配置公钥的页面如下,我们可以在title中给公钥起个名字,名字随便,在key的文本框中填入ssh公钥的内容
如下图
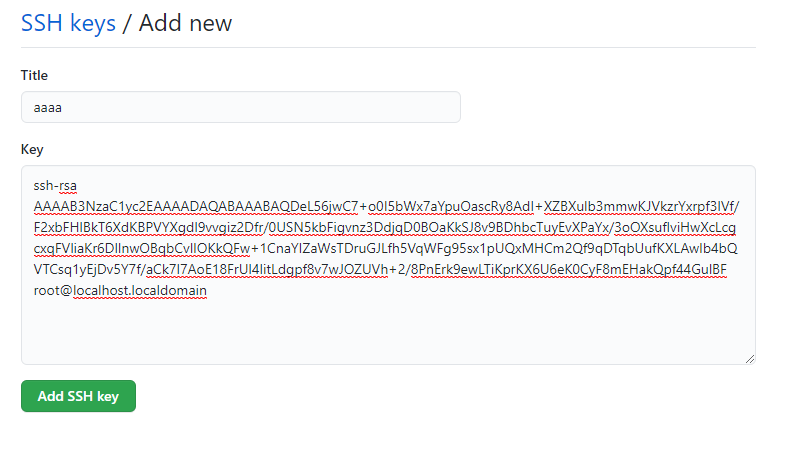
配置完成后,点击上图中的"Add SSH key"绿色按钮,点击按钮后,github会验证你的身份,要求你输入github账户的密码,输入正确的github账户密码后,即可看到你添加的ssh密钥
到目前为止,公钥已经配置完成了,你也可以为github添加多个公钥,以便对应多个私钥使用,当然,配置公钥的操作只需要设置一次,在密钥没有变更的情况下,可以一直使用。
到目前为止,我已经满足了使用ssh形式的仓库地址克隆远程仓库的两个条件。
1、自己的github账号是仓库的成员(之后会描述怎样为仓库添加成员,此处不用纠结)
2、自己的github账号中配置了ssh的公钥,ssh的私钥在自己的本地电脑上
现在,我要做的就是将远程仓库克隆到我的本地电脑上,其他同事也可以在满足上述条件时,将这个远程仓库克隆到自己的本地电脑中,以便所有人都能通过这个远程仓库协作管理代码。那么具体的克隆命令是什么呢?克隆命令如下:
git clone git@github.com:harbour015/test.git
在本地电脑上想要克隆远程仓库的目录中打开git bash,执行上述命令即可通过ssh格式的地址克隆远程仓库,如果你使用的是https的地址,只需要将上述ssh格式的地址换成https格式的地址即可,执行上述命令后返回信息如下:
$ git clone git@github.com:harbour015/test.git
Cloning into 'test'...
warning: You appear to have cloned an empty repository.
从返回信息可以看出,目前test仓库是一个空的仓库,我们可以进入这个仓库,查看一下情况,命令如下
/d/workspace/git
$ cd test
/d/workspace/git/test (master)
$ ls -la
total 12
drwxr-xr-x 1 zz 197121 0 1月 30 11:39 ./
drwxr-xr-x 1 zz 197121 0 1月 30 11:39 ../
drwxr-xr-x 1 zz 197121 0 1月 30 11:39 .git/
/d/workspace/git/test (master)
$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
从上述信息可以看出,除了.git目录,目前test仓库中还什么都没有,也没有任何提交,这是正常的,因为目前远程仓库中就是什么也没有的,此刻,在本地仓库中执行"git remote -v"命令,即可看到当前本地仓库对应的远程仓库,如下
/d/workspace/git/test (master)
$ git remote -v
origin git@github.com:harbour015/test.git (fetch)
origin git@github.com:harbour015/test.git (push)
从上述返回信息可以看出,当前仓库对应的远程仓库的地址就是"git@github.com:harbour015/test.git",你可能会有疑问,为什么有两条记录呢?仔细观察上面两条记录,地址是一样的,但是地址后面分别有 (fetch)和(push)标记,没错,这两条记录分别对应的拉取操作和推送操作,也就是说,拉取操作对应的远程仓库地址"git@github.com:harbour015/test.git",这个远程仓库的名字是"origin ",同理,推送操作对应的远程仓库地址"git@github.com:harbour015/test.git",这个远程仓库的名字是"origin ",你也可以这样理解,origin仓库就是当前本地仓库对应的远程仓库,一个远程仓库会对应两条记录,两条记录分别对应了拉取操作和推送操作的地址,通常情况下,一个远程仓库的拉取地址和推送地址是同一个仓库地址,虽然可以通过命令,将拉取地址和推送地址设置为不同的仓库地址,但是git不推荐我们这样做,一些特殊的使用场景此处暂且不聊,我们只需要知道,默认情况下,当你将远程仓库克隆到本地以后,本地仓库对应的远程仓库默认的名字就叫"origin","origin"这个名字也是可以手动设置的,在没有需求的情况下,我个人不会去修改远程仓库的默认名称。
看到这里,你肯定已经明白了,当我们将远程仓库克隆到本地以后,本地仓库默认的上游仓库就是远程仓库,其实,我们也可以手动的设定某个本地仓库的上游远程仓库,这些都是后话,我们之后再聊。
我们现在就可以在本地仓库中完成各种工作了,比如,创建文件、创建提交等等git操作,与之前唯一不同的是,本地仓库和远程仓库是有对应关系的,本地仓库中的分支也是与远程仓库中的分支对应的,虽然我们之前创建的远程仓库是空的,但是也会有一个默认的master分支,当你克隆到本地时,本地仓库的master分支与远程仓库的master分支就是对应的,如果你在本地仓库中创建了新的new分支,那么当你将本地仓库的中的新内容推送到远程仓库时,本地仓库的new分支就会被推送到远程仓库中,随之远程仓库也会出现new分支,如果此时别的同事从远程仓库拉取更新,就会看到你推送到远程仓库的new分支,new分支也可以被同事通过远程仓库拉取同事的本地电脑中,同事也可以在他的电脑中对new分支创建新提交,然后再将他本地的new分支的新提交推送到远程仓库,就这样来回来去,来来回回的更新,从而实现了通过远程仓库进行协作的目的,同理,同事在他本地电脑中创建的新分支也可以推送到远程仓库中,我们也可以通过远程仓库获取别人创建的分支。
现在,我们就来创建一些测试文件、创建一些提交,然后推送到远程仓库中吧,在本地仓库中执行如下命令
$ git commit -m "first commit"
[master (root-commit) 89e4e23] first commit
1 file changed, 1 insertion(+)
create mode 100644 testfile1
如上所示,我们添加了一个testfile1文件,并且在本地库中创建了第一个提交,此时,如果使用" git branch -vv"命令就可以查看到本地分支与远程仓库分支的对应关系,如下:
/d/workspace/git/test (master)
$ git branch -vv
* master 89e4e23 [origin/master: gone] first commit
从返回信息中可以看到,本地仓库的master分支与远程仓库origin的master分支是对应的,换句话说就是,origin/master分支时本地master分支的上游分支,也就是说,本地的master分支与远程仓库origin的master分支已经建立起了关系,当你在本地推送master分支时,master分支的新内容应该被推送到origin仓库的master分支中,当你在本地拉取master分支时,origin仓库的master分支中的新内容会被拉取到本地的master分支中。
那么现在,我们就来实际操作一下,看看怎样将本地的master分支中新产生的内容推送到远程仓库中,由于一开始远程仓库是空的,现在本地仓库中产生了新内容,所以我们需要将新内容推送到远程仓库中,以便其他同事可以通过远程仓库获取到最新的master分支中的内容。
我们可以在本地仓库中执行"git push origin master:master"命令,"git push origin master:master"命令的作用是将本地的内容推送到远程origin仓库中,推送的本地分支名是master,远程分支名也是master,没错,"master:master"中冒号左边的master代表你要推送的本地master分支,冒号右边的master代表推送到远程仓库中的master分支 ,命令的执行效果如下:
/d/workspace/git/test (master)
$ git push origin master:master
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 206 bytes | 206.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To github.com:harbour015/test.git
* [new branch] master -> master
可以看到,本地的master分支已经成功的推送到了远程仓库的master分支中,
回到你的github页面中,能够看到远程仓库中master分支中已经可以看到对应的文件了。
此时,其他同事也可以从远程仓库的master分支中获取到最新的testfile1中的文件内容了,具体的操作咱们后面再进行演示。
刚才我们执行的push命令是"git push origin master:master",本地分支的分支名与远程分支的分支名是相同的,你可能会问,在推送分支时,远程分支与本地分支的分支名能不能不同呢?是可以的,我们现在就来试试,当前的状态是,本地仓库和远程仓库中都只有一个master分支,我们现在在本地仓库中执行如下命令试试:
/d/workspace/git/test (master)
$ git push origin master:m1
Total 0 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a pull request for 'm1' on GitHub by visiting:
remote: https://github.com/harbour015/test/pull/new/m1
remote:
To github.com:harbour015/test.git
* [new branch] master -> m1
如你所见,我在本地仓库中执行了"git push origin master:m1"命令,表示将本地的master分支推送到远程origin仓库的m1分支中,但是在执行上述命令之前,远程仓库中并没有名为m1的分支,那么执行上述命令后,我们到github页面中看看,会不会有m1分支呢?刷新github页面,点击分支按钮(如下图),可以看到,远程仓库中多出了一个m1分支
由此可见,当远程仓库中没有m1分支时,如果在本地执行"git push origin master:m1"命令,则会在远程仓库中新建m1分支,并且将本地master分支中的内容推送到新建的远程的m1分支中,换句话说就是,当远程仓库中没有m1分支时,我们可以借助上述命令,基于本地的master分支,在远程仓库中创建一个名为m1的分支。
之前说过,使用"git branch -vv"命令可以查看到本地分支与远程分支的对应关系,那么此刻我们来看看,master分支的上游分支是master分支还是m1分支,如下:
/d/workspace/git/test (master)
$ git branch -vv
* master 89e4e23 [origin/master] first commit
可以看到,本地仓库的master分支的上游分支仍然是master分支,而不是m1分支,所以不用担心,你的推送操作不会影响默认的上游分支的设置。
其实,本地分支对应的上游分支都是可以手动进行设置的,也就是说,你也可以将本地master分支的上游分支设置为其他远程分支,但是通常情况下,为了方便记忆,都会将远程同名分支设置为上游分支,具体设置上游分支的方法我们之后再聊,现在我们先来聊聊默认使用同名的上游分支有什么好处,除了刚才提到的方便记忆,还有一个好处就是在执行推送操作时,能够使用更加简短的命令进行推送,比如,本地master的上游分支名也是master,是同名的,那么当你想要将本地的master分支中的新提交推送到远程分支的master分支时,可以直接在本地的master分支中执行"git push"命令(注意:不同版本的git执行此命令的效果不同,之后咱们再详细解释),执行"git push"命令不用指定远程仓库的名称,也不用指定本地分支的名称和远程分支的名称,也就是说," git push origin master:master"可以直接简化成" git push",是不是很方便,我们来试试,先创建一个新的提交,然后直接用"git push"命令推送,如下:
/d/workspace/git/test (master)
$ echo testfile2 > testfile2
/d/workspace/git/test (master)
$ git add testfile2
/d/workspace/git/test (master)
$ git commit -m "add testfile2"
[master debb288] add testfile2
1 file changed, 1 insertion(+)
create mode 100644 testfile2
/d/workspace/git/test (master)
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 271 bytes | 271.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To github.com:harbour015/test.git
89e4e23..debb288 master -> master
如上述命令所示,我们新创建了一个测试文件testfile2,并且针对这个新文件创建了一个新提交,我们在master分支中直接执行"git push"命令,即可将本地master分支的新提交推送到远程仓库的master分支中,你可以去github的页面中刷新核实一下,就可以看到对应的testfile2文件了。
注意:刚才提到过,在不同版本的git中执行"git push"命令的效果是不同的,这里来描述一下具体有什么不同,在1.x版本的git中,"git push"命令会推送所有与上游分支同名的本地分支到远程,而在2.x版本的git中,"git push"命令只会在当前分支与上游分支同名的情况下推送当前分支到远程,换句话说就是,无论是1.x还是2.x的版本,使用"git push"命令推送分支到远程都有一个共同的前提,这个前提就是本地分支需要有对应的上游分支,并且本地分支与上游分支必须同名,这是使用"git push"命令的默认的前提条件,但是在1.x的git中,"git push"命令会推送所有满足前提条件的分支,而在2.x的git中,"git push"命令只会在符合前提条件时推送当前分支。其实无论是在1.x版本还是在2.x版本中,我们都可以对"git push"命令的默认行为进行设置,通过"push.default"属性就能够控制"git push"的默认条件与行为,1.x与2.x的默认行为不同就是因为不同版本中"push.default"属性的值不同,此处我们不用深究,了解即可。
现在,我们在本地仓库中,创建一个新的分支,在新分支上创建一些提交,然后推送到远程仓库中,以便再次熟悉一下push操作,先来创建新分支并且创建新提交,命令如下:
/d/workspace/git/test (master)
$ git checkout -b new
Switched to a new branch 'new'
/d/workspace/git/test (new)
$ echo testfile3 > testfile3
/d/workspace/git/test (new)
$ git add testfile3
/d/workspace/git/test (new)
$ git commit -m "add testfile3 in new branch"
[new 36c77e7] add testfile3 in new branch
1 file changed, 1 insertion(+)
create mode 100644 testfile3
如上命令所示,我们基于master分支创建了一个new分支,并且创建了一个新的测试文件和一个新的提交。
此时,我想要将本地的new分支同步到远程仓库中,该怎么办呢?能不能直接使用"git push"命令推送呢?我们来试试,执行命令后附发现返回信息如下:
/d/workspace/git/test (new)
$ git push
fatal: The current branch new has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin new
从返回信息可以看到,推送失败了,失败的原因也已经告诉了我们,失败的原因是new分支没有对应的上游分支,刚才在介绍"git push"命令的时候,就强调过默认的前提条件,条件就是本地分支必须有对应的上游分支,而且上下游分支必须同名,根据提示信息可以看出,"git push"命令执行失败的原因是因为new分支没有上游分支造成的,那么我们执行"git branch -vv"命令看看,看看具体的情况是什么样的
/d/workspace/git/test (new)
$ git branch -vv
master debb288 [origin/master] add testfile2
* new 36c77e7 add testfile3 in new branch
从上述信息可以看出,master的上游分支是origin/master,而new分支却没有对应的上游分支。
为什么master分支默认就有同名的上游分支,而我们创建的new分支就没有对应的上游分支呢?
原因就是,master分支从一开始就存在于远程仓库中,而new分支是我们在本地新建的,并不存在于远程仓库中。换话说就是,当我们将远程仓库克隆到本地时,master分支就已经存在于远程仓库中了,虽然远程仓库被创建时是一个空的仓库,但是远程仓库默认也是存在master分支的,当我们将远程仓库克隆到本地时,远程仓库中的master分支也会被克隆到本地,所以本地仓库中的master分支会自动将远程仓库的master分支设置成上游分支, 但是new分支则不同,new分支是我们在本地新创建的分支,new分支并不存在于远程仓库中,所以本地的new分支并不会自动设置对应的上游分支,于是,当我们在new分支中执行"git push"命令推送当前分支时,会提示没有对应的上游分支。
由于目前远程仓库中还没有new分支,所以我们可以先将本地new分支推送到远程仓库中,然后再手动的将本地的new分支的上游分支设置为远程仓库中的new分支,上述操作需要分两步完成,先推送new分支到远程,然后设置本地的上游分支为远程分支,其实我们也可以将上述两步合并成一步去完成,我们可以直接执行"git push --set-upstream origin new:new"命令,此命令会在推送本地new分支到远程仓库的同时,直接将本地new分支的上游分支设置为远程仓库中的new分支,实际效果如下
/d/workspace/git/test (new)
$ git push --set-upstream origin new:new
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 306 bytes | 306.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a pull request for 'new' on GitHub by visiting:
remote: https://github.com/harbour015/test/pull/new/new
remote:
To github.com:harbour015/test.git
* [new branch] new -> new
Branch 'new' set up to track remote branch 'new' from 'origin'.
/d/workspace/git/test (new)
$ git branch -vv
master debb288 [origin/master] add testfile2
* new 36c77e7 [origin/new] add testfile3 in new branch
从上述命令可以看出,当我们执行"git push --set-upstream origin new:new"命令后,本地new分支的上游分支自动设置成了"origin/new"分支,其实我们只是在原来推送分支的命令的基础上,添加了一个"--set-upstream"选项,就可以达到推送本地分支到远程的同时设置本地上游分支的效果了,这时我们可以查看github的页面,会发现new分支已经推送到了远程仓库中。
如果你和我一样,使用的是2.x版本的git,那么你可以使用短选项"-u"代替上述命令中的长选项"--set-upstream",也就是说,"git push --set-upstream origin new:new" 和 "git push -u origin new:new" 的效果是一样的,需要注意的是,在早期的1.x版本的git中,只有长选项,没有短选项,由于我们想要推送的本地分支与对应的远程分支同名,所以上述命令还可以简写成"git push -u origin new",效果也是一样的,当执行完上述命令后,由于new分支已经存在了对应的上游分支,而且上游分支和本地new分支同名,之后再在new分支中执行推送操作时,就可以直接执行"git push"命令了(注意:2.x版本默认只会推送当前所在的分支),不用加任何选项和参数,直接执行"git push"命令即可。
刚才说过,我们也可以分两步来完成上述操作:
一、先推送本地分支到远程仓库
二、再手动的设置本地分支的上游分支
我们先聊聊第一步
推送本地分支到远程分支的命令我们已经使用过,如下:
git push origin new:new
由于推送的本地分支和对应的远程分支同名,所以上述命令也可以简写为
git push origin new
当执行完上述命令后,本地new分支已经推送到了远程仓库中。
这时我们再执行第二步,手动的将本地new分支的上游分支设置为远程origin仓库中的new分支,命令如下:
git branch new --set-upstream-to=origin/new
上述命令表示将本地的new分支的上游分支设置为"origin/new"分支,我们也可以使用短选项"-u"代替长选项"--set-upstream-to=",命令如下:
git branch new -u origin/new
上述命令中的本地分支和远程分支的顺序也可以调换,如下命令与上述命令效果相同
git branch -u origin/new new
记忆小技巧:"-u"选项后面指定远程分支名即可,本地分支和远程分支顺序无所谓。
我们也可以省略上述命令中的本地分支名称,当没有指定本地分支名称时,表示默认设置当前分支的上游分支,比如,当前我处于a分支,那么当我执行如下命令时,就表示将本地a分支的上游分支设置为"origin/new"
git branch -u origin/new
上述命令都可以重复执行,所以,我们不仅可以通过上述命令为没有上游分支的本地分支指定上游分支,也可以使用这些命令将本地分支的上游分支修改为其他远程分支,不过,还是之前的建议,建议本地分支和对应的上游远程分支使用相同的名称,以便对应记忆,也方便推送。
之前说过,当你需要确定分支对应的上游分支时,你可以执行"git branch -vv"命令查看,此时,我的执行结果如下
/d/workspace/git/test (new)
$ git branch -vv
master debb288 [origin/master] add testfile2
* new 36c77e7 [origin/new] add testfile3 in new branch
其实," git branch -vv"命令显示出的分支都是"纯本地分支",你可能会问,"纯本地分支"是啥意思???难道还有"不纯的本地分支"吗,先别着急,我们在" git branch -vv"命令的基础上加一个"-a"参数看看,我们使用" git branch -avv"命令看看会显示出什么信息,如下:
/d/workspace/git/test (new)
$ git branch -avv
master debb288 [origin/master] add testfile2
* new 36c77e7 [origin/new] add testfile3 in new branch
remotes/origin/m1 89e4e23 first commit
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
可以看到,使用" git branch -avv"除了显示出了本地的master分支和new分支,还显示出了一些以"remotes/origin/"开头的分支,这些分支又是什么分支呢?
我们可以把这些分支理解成是远程分支在本地仓库中的投影,或者说这些分支就是用于在本地跟踪真正的远程分支的,真正的远程分支存在于github的服务器上,而本地仓库中的这些"remotes/origin/***"分支的主要作用是用于跟踪真正的远程分支,方便我们在本地进行一些操作,这些分支在本地代表了真正的远程分支,我们可以把这种分支称为远程追踪分支,聪明如你一定已经看出来了,当我们为本地分支指定上游分支时,其实指定的就是这些远程追踪分支的名字,这种远程追踪分支在进行推送操作时通常不用在意,当我们执行拉取操作时,会仔细的聊聊这种远程追踪分支,现在只是初步的了解即可。
说了这么多,其实也只是描述了怎样创建远程仓库、怎样克隆远程仓库、怎样设置上游分支以及怎样将本地分支的更新推送到远程等常用操作,到目前都没有描述怎样从远程仓库拉取更新,这些就留到下一篇文章详细聊吧。
有的朋友可能比较在意之前聊到的某个场景,这个场景就是,如果之前有一个只有自己使用的本地仓库,现在突然想要多人协作,能否将已经存在于本地个人仓库中的内容同步到 新创建的远程仓库中供大家使用呢?答案是肯定的,其实方法也很简单,就是将本地私人使用的仓库与新创建的远程仓库建立关系,还记得我们之前使用的"git remote -v"命令吗?我们可以在克隆远程仓库以后,通过此命令查看当前仓库与远程仓库的对应关系,通过此命令可以查看到本地仓库的上游仓库的具体名称和地址,其实,我们也可以手动的指定本地仓库对应的远程仓库,如果一开始的本地仓库只是你个人使用的,现在你想要通过新创建的远程仓库与别人进行协作,只需要手动的将本地仓库的上游仓库指定为新创建的远程仓库即可,指定远程仓库以后,再将需要协作的分支从本地仓库推送到远程仓库中,别人就能够通过远程仓库获取到对应的分支了,那么为本地仓库添加远程仓库的命令是什么呢?命令如下:
git remote add origin git@github.com:harbour015/test.git
你肯定看明白了,你只需要在本地仓库中执行如上命令,即可将本地仓库的远程仓库指定为origin,远程仓库的地址就是"git@github.com:harbour015/test.git",远程仓库名和仓库地址你可以根据实际情况进行设定,当然,这个地址也可以是https格式的地址。
执行上述命令后,本地仓库的远程仓库就指定为origin了,此时再次执行命令"git remote -v"查看远程仓库,就能够看到对应的远程仓库地址了。
你也可以为同一个本地仓库添加多个远程仓库,换句话说就是,你可以为本地仓库添加多个远程仓库的对应关系,这样你在本地仓库执行拉取操作和推送操作时,就需要指定对应的远程仓库名称,比如,我们之前执行的推送命令"git push -u origin new",你可以将命令中的origin换成对应的远程仓库名称就行了。
当你为本地仓库指定远程仓库后,剩下的事情就很好办了,我们只需要将本地仓库的分支推送到远程,就可以通过远程仓库进行协作了,你理解了吗?如果你理解了,可以在github上再创建一个新的远程仓库,当仓库创建后,你会看到远程仓库的地址以及github建议你执行的命令,现在回过头来再看这些命令,是不是感觉很轻松呢?
有时候,公司可能不允许将代码存放在外部服务器中(比如github、gitlab、Bitbucket等这些非公司私有的服务器都属于外部服务器),你可能会需要在公司内部的私有服务器上搭建git托管平台,我自己通常的做法是选择GitLab的安装包(注意是GitLab不是GitHub),GitLab有提供托管服务平台的安装包,我们可以通过安装包快速的在自己的服务器上搭建git托管服务,我们只需要在Centos中配置好对应的yum源,就可以方便快速的在服务器上安装属于自己的代码托管平台了,GitLab的安装包版本也分为社区版和企业版,社区版是免费的,基本功能都有,企业版的功能更多,但是是收费的,记得前一段时间安装GitLab的托管平台社区版本时,有看到GitLab官方建议我们直接安装企业版,我记得当时GitLab官方有段声明,大致意思就是说我们可以直接安装企业版的GitLab托管服务,在没有导入企业版授权的情况下,企业版也只能提供社区版的功能,只有在导入付费授权后,企业版的所有功能才会解锁,也就是说, 我们可以正常的把企业版当做社区版使用,以便随时付费解锁企业版的所有功能,在没有导入付费授权之前,企业版也只会提供社区版的功能,与社区版无二,当然,这只是前一段时间的规定,如果你需要使用GitLab的安装包搭建git托管服务器,还是要搞明白对应的版权要求,以免出现版权问题。
Git之旅(15):远程仓库(二)
我们已经知道,当我们需要多人协作时,可以利用远程仓库交换代码,如果你创建的远程仓库是私有仓库,则只有仓库的成员才能对仓库中的代码进行操作,那么,我们就从"为项目添加成员"这个话题开始吧。
我们先来看看为仓库添加成员的具体操作步骤,仍然使用前文中创建的github私有仓库为例,现在我有两个github账号,两个账号分别是harbour015和harbour016,我用这两个账号模拟仓库的管理员和项目成员,harbour015是仓库的创建者,也就是默认的管理员,harbour016是另一个测试账号,此账号充当项目成员的角色,当然,harbour015也是项目成员之一,只是权限是最高的。
登录harbour015账户,打开上次创建的github仓库,如下图位置
进入项目后,如下图,
第1步:点击Settings菜单
第2步:点击Manager access菜单
第3步:点击 invite a collaborator 按钮即可邀请成员
从下图可以看出,当前仓库还没有任何成员
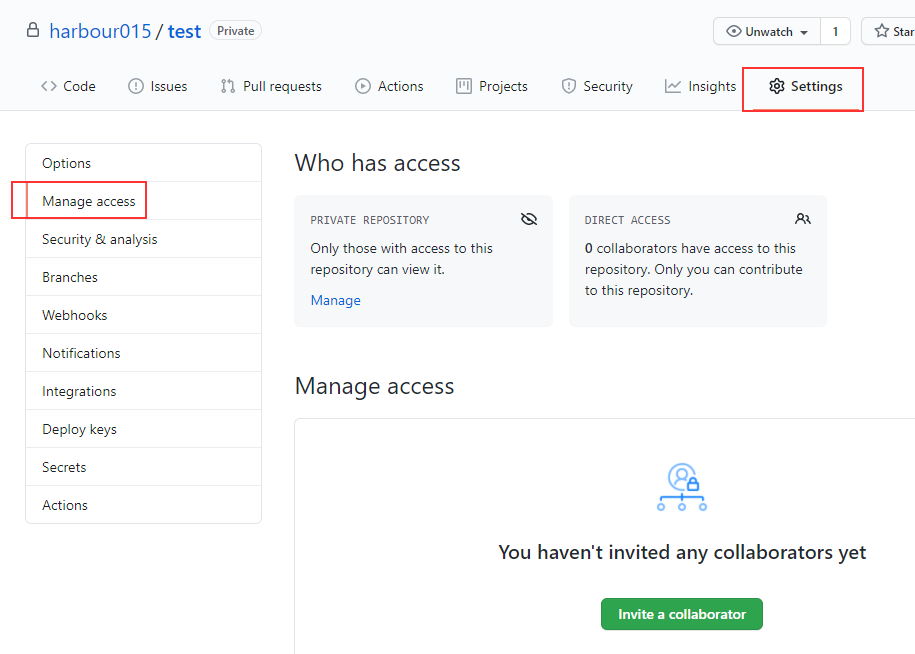
点击上图的邀请成员按钮后,会提示你搜索对应成员的github账号,输入成员的github账号进行搜索,会出现对应的搜索列表,如下图所示,此处输入harbour016,点击对应的账号,会出现一个绿色的按钮,提示添加对应账号到当前的仓库中,点击对应的绿色按钮添加账号即可。
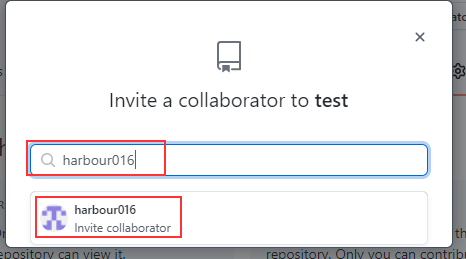
完成上述操作后,页面会自动跳转到 Settings菜单--Manager access菜单中,会看到如下图所示的状态
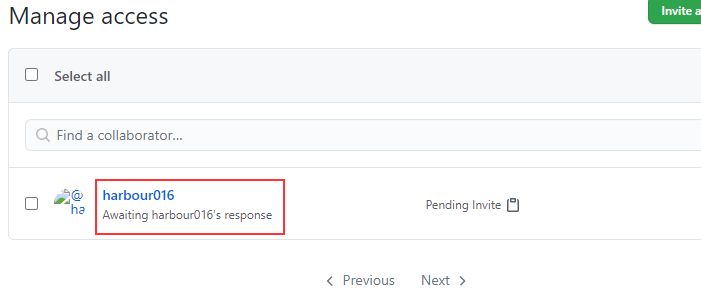
可以看到,我们已经邀请了harbour016成为项目的成员,当前的状态是等待harbour016的响应,也就是说,仓库管理员已经向harbour016账户对应的用户发送了邀请,但是harbour016还没有同意邀请。
现在,我们将角色转换为harbour016用户,harbour016用户的注册邮箱会收到一封邀请邮件,也就是刚才harbour015用户发送的邀请请求,邮件内容如下:
可以看到,邮件的大致内容就是harbour015用户邀请你成为harbour015/test仓库的成员,你可以选择接受或者拒绝,我们点击邮件中的绿色按钮查看邀约,邀约内容如下图
点击上图的接受邀约的按钮,即可成为harbour015/test项目中的一员。
此时,我们再把视角切换回harbour015,再次回到 Settings菜单--Manager access菜单中,如下图所示,可以看到zhushuangyin用户已经变成了仓库的成员。
如果你想要的邀请更多的成员,只要再次点击下图中的"Invite a collaborator"按钮,然后重复上述步骤即可。
目前,harbour015用户和harbour016用户均可对项目中的代码进行操作了。
当然,harbour016用户也需要将自己的公钥配置到自己的github账户中,具体的操作前文已经描述过了,此处不再赘述。为了方便操作,我启动了一台Linux虚拟机,并将root用户的公钥放在了harbour016账户的github账户中,也就是说,目前我在windows中的操作代表harbour015用户,在linux中的操作harbour016用户,以便模拟出多人进行操作时的场景。
我们还是以实际的场景为例,以便更好的将命令融入到实际的应用中。
场景一
场景描述:harbour016用户需要基于master分支开发一个新模块,harbour016用户在本地开发完成,并且测试没有问题以后,需要将最新的代码上传到远程仓库中,以便harbour015用户能够获取到最新的、包含新模块的代码。
我们一起来看一下具体的操作步骤。
步骤1
由于需要基于master分支开发新模块,所以harbour016用户需要获取到最新的master分支的代码,通常的做法是从远程仓库中拉取远程master分支的代码到本地,以便将本地的master分支的代码更新到最新(这个方法我们稍后再说),由于我们刚刚才将harbour016用户添加为仓库的成员,所以harbour016用户可以直接通过clone命令获取到最新的仓库代码,现在,我们就站在harbour016的视角上进行操作。
# git clone git@github.com:harbour015/test.git
# cd test
[root@localhost test]# git branch -avv
* master debb288 [origin/master] add testfile2
remotes/origin/HEAD -> origin/master
remotes/origin/m1 89e4e23 first commit
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
操作如上,harbour016先克隆了仓库,然后进入仓库目录,使用"git branch -avv"命令查看了所有的分支,可以看到,当前处于master分支中,除了master分支,还有很多其他分支,比如m1分支以及new分支,前文中说过,
以remotes/origin开头的分支代表了origin远程仓库中的分支,这些分支实际存放在你的本地仓库中,但是这些分支代表了远程仓库中的分支,你可以把这些分支理解成远程分支在本地的大使,本地通过大使与远程分支进行实际的交互,大使很多时候也需要做一些中转的工作,先不用纠结这些,随着使用的加深,你会有自己的理解,如果我们现在检出到m1分支,本地的m1分支会自动将自己的上游分支设置为origin/m1,也就是说,如果此时检出到m1分支,本地的m1分支和远程的m1分支中的内容是一样的。
步骤2
我们已经通过克隆操作,获取到了远程仓库中的最新的代码,现在我们要做的就是,基于master分支,创建新的分支,因为之前说过,harbour016用户需要基于master分支开发新的模块,为了不影响现有的稳定代码,我们通常会创建一个新的分支来完成新的开发工作,所以,harbour016需要基于master分支创建新的分支,当然,如果需要基于m1分支开发新模块,你也可以先检出到m1分支,然后基于m1分支创建新分支,此处我们还是按照场景中的描述来操作,我们现在就处于master分支中,可以直接创建新分支,命令如下:
# git checkout -b testmodule1
Switched to a new branch 'testmodule1'
创建新分支后,我们再创建一些文件,来模拟新的开发工作
# mkdir testmodule1
# echo 1 > testmodule1/tmfile1
# echo 11 > testmodule1/tmfile2
# git add testmodule1
# git commit -m "init test module1"
[testmodule1 5fb253c] init test module1
2 files changed, 2 insertions(+)
create mode 100644 testmodule1/tmfile1
create mode 100644 testmodule1/tmfile2
如上述操作所示,我们创建了一些文件,模拟新的开发工作,然后在本地的testmodule1分支中创建了新的提交
现在,我们就可以将本地的testmodule1分支推送到远程仓库了,这样做一是可以在远程仓库中有一份代码的备份,二是能够让其他用户通过远程仓库获取到最新的包含新模块的代码,当然,在实际的工作中,开发一个模块不可能这么容易,推送到远程仓库也不代表开发工作完成了,我们可以持续开发,持续的推送,以便实现开发和交付代码的目的,那么现在我们就执行以下推送命令,如下
# git push -u origin testmodule1
当前我们处于testmodule1分支,执行上述命令后,本地的testmodule1分支会被推送到远程仓库中,并且本地的testmodule1分支的上游分支会设置为origin远程仓库中testmodule1分支。
再次回到github页面回到远程仓库,即可看到对应的新分支。
步骤3
刚才的第1步操作和第2步操作都是在harbour016用户的视角下完成的,现在我们把角色切换到harbour015用户,harbour015用户现在需要获取到harbour016用户创建的新分支,以便获取到最新的、包含新模块的代码,对于harbour015用户来说,远程仓库的大多数代码已经存在于本地上了,只不过这些本地的代码并不是最新的代码,harbour015用户现在需要做的就是获取最新代码到本地,以便查看或者操作,那么具体需要怎样操作呢?命令如下
注:目前的视角是harbour015用户,即所有操作在windows中进行。
首先,查看一下当前仓库下的分支,如下
/d/workspace/git/test (m1)
$ git branch -avv
* m1 89e4e23 [origin/m1] first commit
master debb288 [origin/master] add testfile2
new 36c77e7 [origin/new] add testfile3 in new branch
remotes/origin/m1 89e4e23 first commit
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
可以看到,当前处于m1分支中,当前仓库中还没有testmodule1分支,因为我们还没有从远程仓库拉取最新的代码,现在,我们执行如下命令获取一下远程仓库的最新的代码
/d/workspace/git/test (m1)
$ git fetch
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 4 (delta 0), reused 4 (delta 0), pack-reused 0
Unpacking objects: 100% (4/4), 356 bytes | 2.00 KiB/s, done.
From github.com:harbour015/test
* [new branch] testmodule1 -> origin/testmodule1
如上所示,我们执行"git fetch"命令,"git fetch"命令表示获取远程仓库中的最新代码。
仔细观察上述反馈信息,可以发现,执行"git fetch"命令后,有一个新分支被获取到了,这个新分支的名字就是testmodule1, 这个分支其实就是远程origin仓库中的testmodule1分支。
执行上述命令后,我们再次查看当前仓库的所有分支,如下:
/d/workspace/git/test (m1)
$ git branch -av
* m1 89e4e23 first commit
master debb288 add testfile2
new 36c77e7 add testfile3 in new branch
remotes/origin/m1 89e4e23 first commit
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
remotes/origin/testmodule1 5fb253c init test module1
如上所示,我们已经可以看到"remotes/origin/testmodule1"分支了,也就是说,远程仓库中的testmodule1分支的"代表"已经到达本地了,再换句话说就是,真正的存在于github中的"testmodule1"分支已经同步到了本地仓库中的 "remotes/origin/testmodule1"分支中,我们随时可以在本地检出testmodule1分支,以便在本地仓库中进行操作或者查看,我们现在就检出吧,命令如下:
/d/workspace/git/test (m1)
$ git checkout testmodule1
Switched to a new branch 'testmodule1'
Branch 'testmodule1' set up to track remote branch 'testmodule1' from 'origin'.
/d/workspace/git/test (testmodule1)
$ ls
testfile1 testfile2 testmodule1/
/d/workspace/git/test (testmodule1)
$ git branch -avv
m1 89e4e23 [origin/m1] first commit
master debb288 [origin/master] add testfile2
new 36c77e7 [origin/new] add testfile3 in new branch
* testmodule1 5fb253c [origin/testmodule1] init test module1
remotes/origin/m1 89e4e23 first commit
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
remotes/origin/testmodule1 5fb253c init test module1
如上所示,在本地仓库中检出testmodule1分支后,即可看到对应的目录,正是harbour016用户创建的目录和文件,细心如你肯定已经发现了,由于我们刚刚获取到了最新的代码,而且检出testmodule1分支后还没有创建任何新提交到本地的testmodule1分支中,所以本地的"testmodule1"分支和代表远程分支的"remotes/origin/testmodule1"分支的哈希码是相同的,都是5fb253c
说了这么多,其实我们只用了一个新命令,这个命令就是"git fetch"命令,其他的命令在前文中都已经解释过,只有"git fetch"命令是这篇文章中新出现的命令,这个命令在上述场景中的作用就是拉取了最新的远程代码到本次仓库中,但是由于远程仓库中只有testmodule1分支是新内容,所以我们从"git fetch"命令的返回信息中只能看到testmodule1分支的更新信息,如果有其他用户更新了其他分支并推送到了远程仓库中,那么我们执行"git fetch"命令后,也能看到所有更新的分支的信息。
上述场景其实非常简单,我们通过这个简单的场景,学到了一个基础的命令,这个命令就是"git fetch",通过它我们可以把远程仓库的最新代码同步到本地中,如果说的更加详细一点,就是将真正存在于远程服务器中的分支中的新内容同步到本地的"代表"分支中,以便用户再通过"代表"分支进行进一步的操作。如果你没有明白,不用纠结,继续向下看。
场景二
场景描述:场景二是建立在场景一的基础上的,harbor016用户更新了testmodule1分支以及其他一些分支中的代码,harbour015用户现在想要在自己的本地仓库中看到最新的代码该怎么办呢?注意,此场景中只有harbour016用户更新了代码,harbour015没有做任何操作,即使在本地仓库中,也没有进行任何操作,说明此注意事项只是为了让大家不要考虑太多,以免我们自己把自己绕进去。
其实仔细想想,场景二和场景一不是一样的吗?都是一个用户产生新内容,另一个用户获取新内容,没错,两个场景本质上是一样的,只不过我们可以通过不同的命令,去实现我们的目的,先不用多说,来看看具体的命令吧。
步骤1
harbour016用户操作如下
[root@cos76test test]# git branch
master
* testmodule1
[root@cos76test test]# ls
testfile1 testfile2 testmodule1
[root@cos76test test]# cat testmodule1/tmfile1
1
[root@cos76test test]# echo 2 >> testmodule1/tmfile1
[root@cos76test test]# cat testmodule1/tmfile1
1
2
[root@cos76test test]# git commit -am "update tmfile1"
[testmodule1 6b7ad19] update tmfile1
1 file changed, 1 insertion(+)
[root@cos76test test]# git push
Counting objects: 7, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 324 bytes | 0 bytes/s, done.
Total 4 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To git@github.com:harbour015/test.git
5fb253c..6b7ad19 testmodule1 -> testmodule1
如上述命令所示,harbour016用户在本地更新了testmodule1分支中的tmfile1文件,然后创建了提交,提交的哈希码为6b7ad19,然后harbour016用户将最新的提交6b7ad19推送到了远程仓库中。
现在,harbour016用户来修改一下其他分支中的代码,也推送到远程仓库中,命令如下:
[root@cos76test test]# git checkout m1
Branch 'm1' set up to track remote branch 'm1' from 'origin'.
Switched to a new branch 'm1'
[root@cos76test test]# ls
testfile1
[root@cos76test test]# cat testfile1
1
[root@cos76test test]# echo 22222 >> testfile1
[root@cos76test test]# git commit -am "test m1"
[m1 3724eb0] test m1
1 file changed, 1 insertion(+)
[root@cos76test test]# git push
Counting objects: 5, done.
Writing objects: 100% (3/3), 241 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:harbour015/test.git
89e4e23..3724eb0 m1 -> m1
如上所示,harbour016用户修改了m1分支中的testfile1文件,本地创建提交后,将更新推送到了远程仓库中。
目前,我们模拟harbour016用户的操作已经完成了。
步骤2
现在我们将角色转换成harbour015用户,harbour015用户的操作如下。
harbour015现在需要获取到远程仓库中的最新的代码,于是harbour015用户先执行了"git fetch"命令,如下
/d/workspace/git/test (testmodule1)
$ git fetch
remote: Enumerating objects: 13, done.
remote: Counting objects: 100% (11/11), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 7 (delta 1), reused 7 (delta 1), pack-reused 0
Unpacking objects: 100% (7/7), 513 bytes | 2.00 KiB/s, done.
From github.com:harbour015/test
5fb253c..6b7ad19 testmodule1 -> origin/testmodule1
89e4e23..3724eb0 m1 -> origin/m1
可以看到,fetch后有两个分支被更新了,一个testmodule1 分支,一个m1分支,分支更新后,我们能够直接看到更新的内容吗,我们一起来试试看
/d/workspace/git/test (testmodule1)
$ ls
testfile1 testfile2 testmodule1/
/d/workspace/git/test (testmodule1)
$ cat testmodule1/tmfile1
1
什么情况?harbour016用户明明在"testmodule1/tmfile1"文件中加入了一行文本"2",这边更新后为什么没有看到呢?别着急,我们先来执行"git branch -avv"命令,就会发现一些端倪,执行如下:
/d/workspace/git/test (testmodule1)
$ git branch -avv
m1 89e4e23 [origin/m1: behind 1] first commit
master debb288 [origin/master] add testfile2
new 36c77e7 [origin/new] add testfile3 in new branch
* testmodule1 5fb253c [origin/testmodule1: behind 1] init test module1
remotes/origin/m1 3724eb0 test m1
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
remotes/origin/testmodule1 6b7ad19 update tmfile1
从上述命令可以看出,本地的testmodule1分支的当前提交ID为5fb253c,而代表远程分支的"remotes/origin/testmodule1"分支的提交ID为6b7ad19,而6b7ad19正是harbour016用户推送到远程仓库中的提交,看到此处你肯定已经明白了,"git fetch"命令只会将真正的远程分支中的更新同步到本地的"代表"分支中,并不会将更新一并同步到真正的"纯"本地分支中,这样描述非常不专业,但是方便理解,我觉得你肯定明白我要表达的意思了吧,那么我们怎样才能把代表分支中的更新同步到本地工作区中的分支中呢?其实很简单,我们只需要执行一下合并操作就行了,命令如下:
/d/workspace/git/test (testmodule1)
$ git merge origin/testmodule1
Updating 5fb253c..6b7ad19
Fast-forward
testmodule1/tmfile1 | 1 +
1 file changed, 1 insertion(+)
/d/workspace/git/test (testmodule1)
$ cat testmodule1/tmfile1
1
2
命令如上,当前我们就处于testmodule1分支中,当我们执行"git merge origin/testmodule1"命令后,相当于将 "remotes/origin/testmodule1"分支中的内容合并到了"testmodule1"分支中,所以,对应的更新也一并进入到了"testmodule1"分支中。而且,从上述提示信息可以看出,这次合并操作使用了Fast-forward模式进行了合并,所以没有提示我们输入注释信息,因为没有创建新的提交,所以并不用填写注释,如果你忘记了什么是Fast-forward模式,请回顾前文。
你可能会问,为什么场景一中就没有执行merge操作,而是fetch后直接checkout就可以呢?那是因为,在场景一中还从来没有检出过testmodule1分支,所以fetch后的检出操作就是第一次检出操作,检出后的本地分支自然和"remotes/origin/testmodule1"分支是一样的,所以不用再次执行merge操作,而在场景二中,之前就已经检出过testmodule1分支,所以fetch以后,检出过的testmodule1分支与fetch后的"remotes/origin/testmodule1"分支是不一样的(因为远程仓库有更新,所以不一样,如果远程仓库没有更新,即使fetch后也是一样的),所以需要在fetch后执行merge操作,以便更新同步到之前检出过的testmodule1分支中。
同样的道理,由于刚才fetch时,还显示了m1分支的更新,我们现在切换回m1分支,再来熟悉一遍操作。
/d/workspace/git/test (testmodule1)
$ git checkout m1
Switched to branch 'm1'
Your branch is behind 'origin/m1' by 1 commit, and can be fast-forwarded.
(use "git pull" to update your local branch)
/d/workspace/git/test (m1)
$ cat testfile1
1
可以看到,当我们检出到m1分支后,git的提示信息中显示,你的分支比 'origin/m1' 分支落后1个提交,也就是说,本地检出的m1分支比远程仓库的m1分支落后一个提交,git之所以知道本地的m1分支比远程仓库的m1落后一个提交,就是因为fetch命令已经将远程的信息同步到了"remotes/origin/testmodule1"分支中,所以,git可以知道本地的分支是落后的,而且,从上述提示信息可以看出,当前的情况下,可以使用fast-forwarded模式进行合并,因为harbour015用户并没有对本地的m1分支创建新提交,只有远程分支中存在新的提交,这种情况下可以满足ff模式的条件,所以可以使用ff模式进行合并。
此刻,执行merge命令即可,操作如下
/d/workspace/git/test (m1)
$ git merge origin/m1
Updating 89e4e23..3724eb0
Fast-forward
testfile1 | 1 +
1 file changed, 1 insertion(+)
/d/workspace/git/test (m1)
$ cat testfile1
1
22222
其实,上述fetch+merge的操作步骤可以通过一条命令完成,这条命令就是"git pull"命令,也就是说,"git pull"命令会完成"git fetch"命令和"git merge"命令两条命令的工作,为了实际演示"git pull"命令,我们重新来模拟一遍上述场景,即A用户更新,B用户不进行操作,只在A用户更新完的情况下拉取代码到本地,操作如下:
由于当前处于harbour015用户下,我们就用harbour015用户来进行更新操作吧,harbour015用户操作如下
/d/workspace/git/test (m1)
$ echo 333 >> testfile1
/d/workspace/git/test (m1)
$ git commit -am "add 333 in testfile1"
[m1 2a3e7d5] add 333 in testfile1
1 file changed, 1 insertion(+)
/d/workspace/git/test (m1)
$ git checkout testmodule1
Switched to branch 'testmodule1'
Your branch is up to date with 'origin/testmodule1'.
/d/workspace/git/test (testmodule1)
$ echo 3 >> testmodule1/tmfile1
/d/workspace/git/test (testmodule1)
$ git commit -am "add 3 in tmfile1"
[testmodule1 a4b3797] add 3 in tmfile1
1 file changed, 1 insertion(+)
/d/workspace/git/test (testmodule1)
$ git push --all
如上述操作所示,harbour015用户分别在m1分支和testmodule1分支中创建了新提交,并且使用"git push --all"命令一次性将所有分支的更新推送到了远程仓库中(注:我的windows和linux中安装的git都是2.x版本的git,所以一次性推送所有满足条件的分支需要加上--all选项)
上述操作完成后,我们将视角切换到harbour016用户,来执行一下"pull"命令,以便测试此命令的拉取效果,在执行pull命令之前,我们先来看一下当前仓库的状态,如下:
[root@cos76test test]# git branch -avv
* m1 3724eb0 [origin/m1] test m1
master debb288 [origin/master] add testfile2
testmodule1 6b7ad19 [origin/testmodule1] update tmfile1
remotes/origin/HEAD -> origin/master
remotes/origin/m1 3724eb0 test m1
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
remotes/origin/testmodule1 6b7ad19 update tmfile1
[root@cos76test test]# cat testfile1
1
22222
如上述命令所示,当前我们处于m1分支中,查看testfile1文件的内容,只有两行,当前状态下m1分支和"remotes/origin/m1"分支的哈希码都是3724eb0,现在,我们来执行pull命令,在执行命令之前,先确定你已经处于m1分支中,由于我们当前就处于m1分支,所以可以直接执行如下命令:
[root@localhost test]# git pull origin m1
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From github.com:harbour015/test
* branch m1 -> FETCH_HEAD
Updating 3724eb0..2a3e7d5
Fast-forward
testfile1 | 1 +
1 file changed, 1 insertion(+)
[root@cos76test test]# cat testfile1
1
22222
333
[root@cos76test test]# git branch -avv
* m1 2a3e7d5 [origin/m1: ahead 1] add 333 in testfile1
master debb288 [origin/master] add testfile2
testmodule1 6b7ad19 [origin/testmodule1] update tmfile1
remotes/origin/HEAD -> origin/master
remotes/origin/m1 3724eb0 test m1
remotes/origin/master debb288 add testfile2
remotes/origin/new 36c77e7 add testfile3 in new branch
remotes/origin/testmodule1 6b7ad19 update tmfile1
如上所示,当执行"git pull origin m1"命令后,更新直接同步到了testfile1 文件中,再次执行"git branch -avv"命令查看分支信息,可以发现,m1分支和"remotes/origin/m1"分支的哈希码都变成了2a3e7d5,效果很明显,pull操作一次性的完成了fetch操作和merge操作的工作,"git pull origin m1"命令表示拉取origin远程仓库中的m1分支到当前分支,由于我们当前就处于m1分支,所以,执行"git pull origin m1"命令就相当于直接将本地的m1的分支更新到最新。
同理,我们可以用同样的方法对testmodule1分支执行pull操作,先checkout到testmodule1分支,然后执行pull命令:操作如下
git checkout testmodule1
git pull origin testmodule1
没错,当你想要pull某个分支时,一定要先切换到对应的分支,因为"git pull"命令的默认动作就是pull指定的远程分支到当前分支,搞明白这一点,再来看其他"pull"命令就方便理解了,我们来看看如下命令是什么意思:
git pull origin Abr:Abr
我们来猜猜上述命令是什么意思···
上述命令的意思是,将远程的Abr分支pull到本地的Abr分支,同时,将远程的Abr分支pull到本地的当前所在分支,如果我们当前就处于Abr分支,那么上述命令的作用就是将远程Abr分支的最新更新拉取到本地Abr分支,如果我们当前处于非Abr分支,那么上述命令就会将远程Abr分支更新到本地Abr分支的同时,也将远程Abr分支pull到本地分支上,由于pull命令本身就有merge的操作,所以当合并的分支名不同时,出现冲突的概率会比较大,我们先不考虑冲突的情况,后文中自然会遇到,当前文章我们刻意的避免了冲突情况的发生,以便从简单的场景理解这些命令的本质用法。
我们再来猜猜如下命令是什么意思···
git pull
没错,这次我们什么选项都没有加,那么执行上述命令的作用是什么呢?
上述命令的作用就是,pull当前分支的同名上游分支,并且将其他分支的同名上游分支的更新fetch到本地,这样说不容易理解,我们举个例子,比如,当前仓库有A、B、C三个分支,这3个分支都已经checkout到本地的仓库当中了,假设当前我们处于本地的A分支中,那么,当我们执行"git pull"命令时,会有几种情况
情况1:当我们处于A分支,A分支的同名上游分支没有更新,但是B分支或者C分支的同名上游分支有更新,执行"git pull"命令,你会看到git对B分支或者C分支执行了fetch操作,但是只是fetch,没有对应的自动merge操作,当然,如果B分支和C分支的同名上游分支都有更新,就都会fetch。
情况2:当我们处于A分支,A分支的同名上游分支有更新,B分支或者C分支的同名上游分支也有更新,执行"git pull"命令,你会看到git对A分支执行了pull操作(即fetch+merge),对B分支或C分支执行了fetch操作,当然,如果B分支和C分支的同名上游分支都有更新,就都会fetch。
总结一下就是,当本地分支与上游分支同名时,"git pull"命令会对当前分支执行pull操作,对其他分支执行fetch操作,具体的差异主要取决于对应的远程分支有没有更新。
具体的测试此处就不再赘述了,快动手试试吧。
小结:
我们来总结一下这边文章中提到的命令的用法
git push --all
此命令表示当本地分支与上游分支同名时,push所有分支的更新到对应的远程分支。
git fetch
此命令表示获取远程仓库的更新到本地,但是不会更新本地分支中的代码。
git pull remote branchA
此命令表示将remote仓库的A分支pull到本地当前所在分支,如果你想要pull到本地的A分支,需要先checkout到本地A分支中。
git pull remote branchA:branchB
此命令表示将remote仓库的A分支pull到本地的B分支,在成功的将远程A分支pull到本地B分支后(如果远程A到本地B的pull操作失败了,后面的操作不会执行),再将远程A分支pull到本地的当前所在的分支。
git pull
此命令表示当本地分支与上游分支同名时,对当前分支执行pull操作,对其他分支执行fetch操作,具体的差异主要取决于对应的远程分支有没有更新。